AdaBatch
Our job is to reproduce this paper:《AdaBatch: adaptive batch sizes for training deep neural networks》 In our work, we use adabatch technology to train the neural network architecture only in Alexnet, Resnet-20 and VGG on cifar-10 and cifar-100 datasets. We have done a single nividia Tesla T4 GPU and three GPUs parallel training experiments.
Numerical experiments for 《AdaBatch: adaptive batch sizes for training deep neural networks》
========
Training deep neural networks with Stochastic Gradient Descent, or its variants, requires careful choice of both learning rate and batch size. While smaller batch sizes generally converge in fewer training epochs, larger batch sizes offer more parallelism and hence better computational efficiency. We have developed a new training approach that, rather than statically choosing a single batch size for all epochs, adaptively increases the batch size during the training process.
Our method delivers the convergence rate of small batch sizes while achieving performance similar to large batch sizes. We analyse our approach using the standard AlexNet, ResNet, and VGG networks operating on the popular CIFAR-10, CIFAR-100, and ImageNet datasets. Our results demonstrate that learning with adaptive batch sizes can improve performance by factors of up to 6.25 on 4 NVIDIA Tesla P100 GPUs while changing accuracy by less than 1% relative to training with fixed batch sizes.
Details can be found in our companion paper:
A. Devarakonda, M. Naumov and M. Garland, "AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks", Technical Report, ArXiv:1712.02029, December 2017.
CIFAR. Our implementation of AdaBatch for the CIFAR-10 and CIFAR-100 datasets is contained in:
1.Single GPU
adabatch_cifar.py
2.Multi GPU
three nodes:
cifar_dis.py --world-size 3 --rank 0
cifar_dis.py --world-size 3 --rank 1
cifar_dis.py --world-size 3 --rank 2使用 SGD 训练神经网络的时候需要精挑细选一个合适的批量,较小的 batch size 通常在较少的训练时间内神经网络就能收敛,但较大的 batch size 提供了更多的并行性,从而提高了计算效率。
论文(2017年,NVIDIA)《AdaBatch: adaptive batch sizes for training deep neural networks》开发了一种新的训练方法,在训练过程中自适应地增加批量,而不是在所有时间段选择固定大小的批量。原文的方法表现了小批量的收敛速度,同时实现了类似于大批量的性能。
原文的实验使用 Tesla P100 gpu 在 CIFAR10、CIFAR-100、ImageNet 数据集上训练了 AlexNet、ResNet 和 VGG 网络来分析 AdaBatch 方法。
原文的实验结果表明,在 4 个 NVIDIA Tesla P100 gpu 上,采用 AdaBatch 的训练可以提高性能达 6.25 倍(在单个 gpu 上也能小幅提高,但是 AdaBatch 能达到大 batch size 的能力使这个技术在多 gpu 并行上效率更高),而相对于采用固定批量的训练,准确率的变化不到1%(固定小批量的测试精度最高,固定大批量的训练有时甚至不收敛)。
结果也独立地验证了 AdaBatch 实际上可以取代学习率的衰减,并提高性能。特别地,原文证明了 AdaBatch 调度可以产生学习速率调度无法实现的加速。
-
程序
原文实验代码官方已经开源在 GitHub:https://github.com/NVlabs/AdaBatch。
由于 Python 和 PyTorch 的版本更迭,需要稍加 debug 后方可运行。代码基本按照原文和实验结果的图表来设定参数。
这个仓库的代码是我们稍加 Debug 完成的。使用 jupyter notebook 和 matplotlib 的绘图程序和保存下来的 npz 格式的实验数值在这个 目录 下。
-
实验设置及结果
根据原文的实验设置,我们的复现实验使用 PyTorch1.6 和 1 块 NVIDIA-Tesla T4 gpu,在 CIFAR-10 和 CIFAR-100 数据集上训练 VGG、ResNet 和 AlexNet。在这些实验中,使用动量为 0.9,权重衰减为
$5×10^{-4}$ 的 SGD,进行 100 个 epochs 的训练。初始学习率是 α = 0.01,每 20 个 epochs 衰减一次。对于 AdaBatch 方法,我们将学习率衰减权重设为 0.75,同时在相同的 20 个 epochs 间隔内成倍增加批量。0.75 倍的学习率衰减和批量倍增相结合,可以得出批量固定的情况下,有效学习率衰减的权重为 0.375;因此,我们使用学习率衰减为 0.375 的 FixedBatch(固定批量) 实验进行最直接的比较。
对于 AdaBatch,批量在 100 个 epochs 内每 20 个 epochs 增加一倍,VGG19_BN 和 ResNet-20 的批量从 128 动态增大到 2048,AlexNet 的批量则从 256 倍增到 4096。
对于 FixedBatch,批量在 100 个 epochs 内固定不变,分别进行最小 FixedBatch 和最大 FixedBatch 两次实验,对于 VGG19_BN 和 ResNet-20,固定批量是 128 和 2048,对于 AlexNet,固定批量是 256 和 4096。
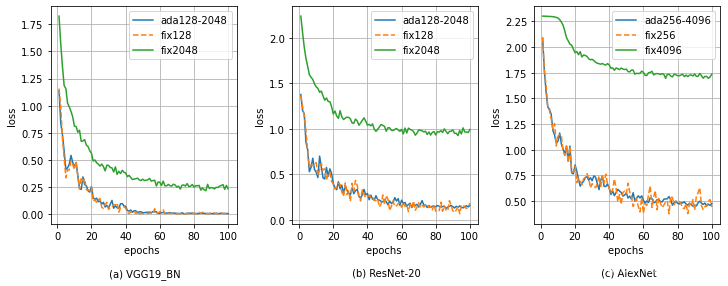
上图显示了在 CIFAR-10 数据集上训练 VGG19_bn、ResNet-20 和 AlexNet 的 loss 下降曲线。可以看到在 100 个 epochs 内,loss 值在第 60 个 epoch 后开始趋于平缓,说明神经网络在 100 个 epochs 内基本能完成训练。
我们也能看到 AdaBatch 和最小的 FixedBatch(128、256)的 loss 曲线几乎一致,但在最大的 FixedBatch(2048、4096)的时候,神经网络的 loss 相对于前者的没有下降足够低,说明固定的大批量训练使神经网络较难收敛,下面的实验测试误差也说明了这个问题。
在 CIFAR-100 数据集上的训练也有同样的表现。

上图显示了 CIFAR-10 数据集上 VGG19_bn、ResNet-20 和 AlexNet 的测试误差。对于 AlexNet,FixedBatch 是 256 和 4096。对于 VGG19 和 ResNet-20,FixedBatch 是 128 和 2048。图上绘制了每个批量设置的一次测试误差。可以看到 AdaBatch 技术的平均测试误差在最小 FxiedBatch(128、256)的 1% 以内,但最大 FxiedBatch(2048、4096)的测试表现与原文有较大差距。

上图显示了相同网络和批量设置下,在 CIFAR-100 数据集上训练得到的类似结果。再次看到,AdaBatch 技术的测试误差在最小 FxiedBatch(128、256)的 1% 以内。但是最大 FixedBatch(2048、4096)的测试误差大得惊人,特别是 AlexNet 在最大 FixedBatch 4096 下的训练误差极大,无法收敛,可以说在 100 个 epochs 内训练无效。
总之,最大 FixedBatch(2048、4096)的实验结果与原文实验相差较大,原因可能是原文选取的是多次实验的最佳结果。但是 AdaBatch 技术和最小 FxiedBatch(128、256)的实验几乎完美复现论文结果。
原文的研究结果表明,学习率衰减策略和批量倍增策略是相关的和互补的,两者都可以用来达到类似的效果测试误差。然而,调整批量提供了额外的优势,即更好的计算效率和可伸缩性,而无需牺牲测试误差,下文的实验将验证这一结论。
| Network | Ada / Fix | Batch Size | Forward Time (speedup) | Backward Time (speedup) |
|---|---|---|---|---|
| VGG19_BN | Fix | 128 | 2406.46 sec. (1×) | 5160.00 sec. (1×) |
| Ada | 128 - 2048 | 2342.10 sec. (1.03×) | 4865.32 sec. (1.06×) | |
| ResNet-20 | Fix | 128 | 1024.36 sec. (1×) | 2105.98 sec. (speedup) |
| Ada | 128 - 2048 | 998.05 sec.(1.03 ×) | 1993.58 sec. (1.06×) | |
| AlexNet | Fix | 256 | 339.57 sec. (1×) | 646.10 sec. (speedup) |
| Ada | 256 - 4096 | 244.06 sec.(1.39 ×) | 493.47 sec. (1.31×) |
上表量化了 AdaBatch 技术带来的一部分的计算效率改进。实验在 CIFAR-100 数据集上训练了 100 个 epochs 的时间。表中省略了最大的 FixedBatch,因为它们没有达到可比的测试误差。表中还省略了 CIFAR-10 的性能结果,因为它们是相似的数据集。对于测试的 ResNet-20 和 AlexNet,可以观察到 AdaBatch 的平均正向和反向传播运行时间比最小的 FixedBatch 更好,我们进行了两次以上的实验,都能轻易验证原文中这两个神经网络的实验效果。
-
多 GPU 性能测试
下面,我们的复现实验使用 PyTorch 的
torch.nn.parallel.DistributedDataParallel(model)模型并行 API 和torch.utils.data.distributed.DistributedSampler(train_dataset)数据并行 API,对 3 个 Tesla T4 gpu 进行并行化,这与原文实验有差距,原文使用 4 个 Tesla P100 并行训练,但我们的超算上的同时空闲 GPU 没这么多,所以只使用了 3 个 T4 gpu。我们在 CIFAR-100 数据集上使用 VGG19_BN 和 ResNet-20 进行了实验,使用动量为 0.9,权重衰减为
$5×10^{−4}$ 的 SGD。AdaBatch 从 128 每 20 个 epochs 倍增到 2048,初始学习率为 0.1,每 20 个周期学习率衰减 0.25 倍。进行 100 个 epochs 的训练。这是 AdaBatch 和 FixedBatch 方法在 CIFAR-100 数据集上的并行训练 VGG19_bn、Resnet-20 的前向(蓝色)、反向(橙色)传播用时和前向(红色)、反向(黑色)传播加速比。左纵轴是运行时间,右纵轴是加速比,横坐标是三个批大小策略(fixed128、adabatch128-2048、multi gpu adabatch128-2048)。图表的条形图表现了一次并行训练的前、反向传播用时,折线图表现了加速比。
与 baseline 固定批量(128)设置相比,我们发现多 gpu 并行训练的 AdaBatch128-2048 的前向传播加速比为 3.28 ×(VGG19_BN)和 2.29 ×(ResNet-20);反向传播加速比为 1.52×(VGG19_BN)和 2.50×(ResNet-20),测试误差小于 2%。请注意,由于众所周知的观察发现,大批量生产速度更快,因此实现了加速。注意到原文的方法扩展到更多的gpu也是有用的,这是由于使用了渐进的批量大小。


原文开发了一个自适应批大小方案 AdaBatch,在训练过程中动态地改变批量大小。综合我们的复现实验,基本可以得出和原文相同的结论:在 AlexNet、ResNet 和 VGG 神经网络架构以及 CIFAR-10、CIFAR-100 和 ImageNet 数据集上使用 AdaBatch 技术,我们可以得到小批量的更好的测试精度,同时获得通常与大批量相关的更高性能。
在我们的复现实验中,最大的 FixedBatch(2048、4096)无法收敛到最小的 FixedBatch(128、256)的测试误差,但是 AdaBatch 可以。这些结果表明,AdaBatch 获得了与最小的 FixedBatch 相同的测试误差,但具有大批量训练的高效优势。由于批量逐渐变大,AdaBatch 很可能获得更高的性能和更快的训练速度。
实验结果还表明,所有 AdaBatch 设置的测试误差曲线与固定小批量曲线非常吻合。AdaBatch 的收敛速度在 Epoch 60 后减慢,但是最终测试误差与其他测试误差最小的曲线相似。这项实验表明,AdaBatch 可以在不显著改变测试误差的情况下,使批量达到更大的值。
A. Devarakonda, M. Naumov and M. Garland, "AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks", Technical Report, ArXiv:1712.02029, December 2017.
B. Official code link:https://github.com/NVlabs/AdaBatch
[CIFAR example code]:https://github.com/bearpaw/pytorch-classification/tree/master/models/cifar
[ImageNet example code]:https://github.com/pytorch/examples/tree/master/imagenet