Code for paper in CVPR2019, 'Shifting More Attention to Video Salient Object Detection'
Authors: Deng-Ping Fan, Wenguan Wang, Ming-Ming Cheng, Jianbing Shen.
[Supplementary material is also attached in the repo]
Paper with code: https://paperswithcode.com/task/video-salient-object-detection

Figure 1: OVerall architecture of the proposed SSAV model.
The last decade has witnessed a growing interest in video salient object detection (VSOD). However, the research community long-term lacked a well-established VSOD dataset representative of real dynamic scenes with high-quality annotations. To address this issue, we elaborately collected a visual-attention-consistent Densely Annotated VSOD (DAVSOD) dataset, which contains 226 videos with 23,938 frames that cover diverse realistic-scenes, objects, instances and motions. With corresponding real human eye-fixation data, we obtain precise ground-truths. This is the first work that explicitly emphasizes the challenge of saliency shift, i.e., the video salient object(s) may dynamically change. To further contribute the community a complete benchmark, we systematically assess 17 representative VSOD algorithms over seven existing VSOD datasets and our DAVSOD with totally ~84K frames (largest-scale). Utilizing three famous metrics, we then present a comprehensive and insightful performance analysis. Furthermore, we propose a baseline model. It is equipped with a saliencyshift-aware convLSTM, which can efficiently capture video saliency dynamics through learning human attention-shift behavior. Extensive experiments1 open up promising future directions for model development and comparison.
The saliency shift is not just represented as a binary signal, w.r.t., whether it happens in a certain frame. Since we focus on an object-level task, we change the saliency values of different objects according to the shift of human attention. The rich annotations, including saliency shift, object-/instance-level ground-truths (GT), salient object numbers, scene/object categories, and camera/object motions, provide a solid foundation for VSOD task and benefit a wide range of potential applications.

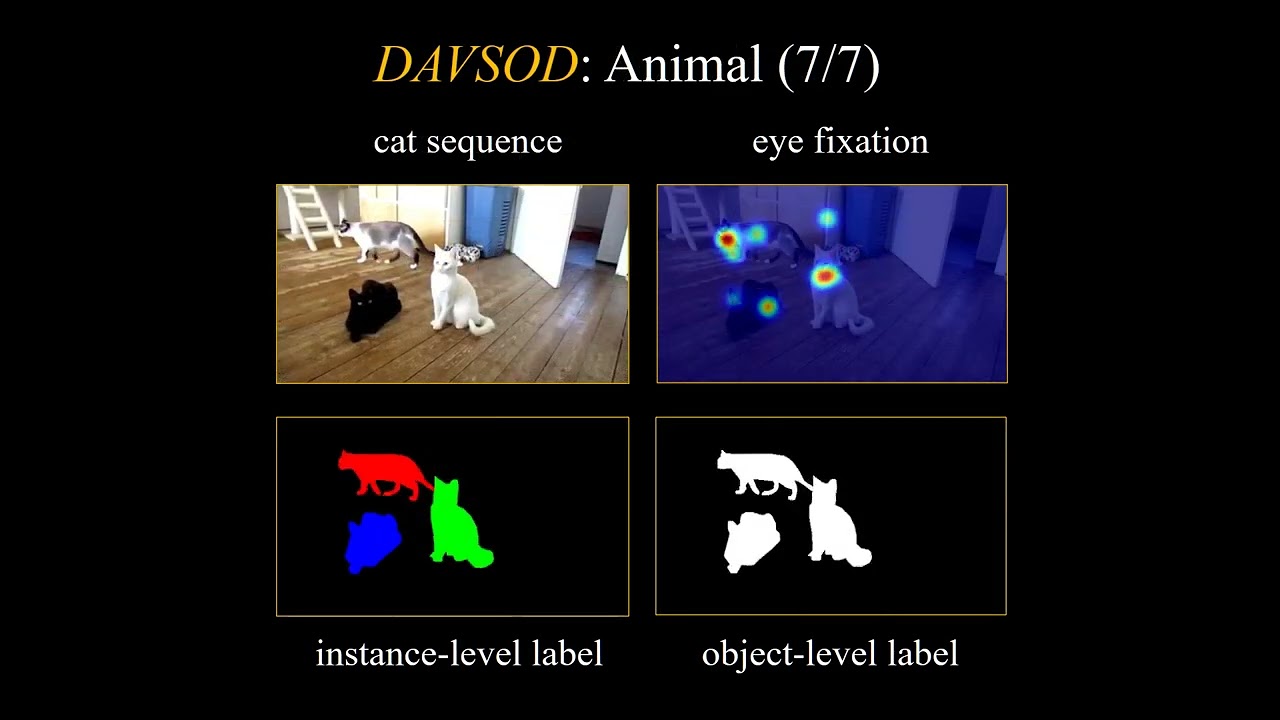
Figure 2: Annotation examples of our DAVSOD dataset.

Figure 3: Statistics of the proposed DAVSOD dataset.
Figure 3 shows (a) Scene/object categories. (b, c) Distribution of annotated instances and image frames, respectively. (d) Ratio distribution of the objects/instances. (e) Mutual dependencies among scene categories in (a).
-
DAVSOD dataset.
- Training Set (3.05G, 61 sequences) | Baidu Pan(fetch code: wvi3) | Google Drive (Updated link: 2021-02-18)
- Validation Set (2.30G, 46 sequences) | Baidu Pan(fetch code: 9tbb) | Google Drive (Updated link: 2021-02-18)
- Test Set (4.89G, 80 sequences) | Baidu Pan | Google Drive (Updated link: 2021-02-18)
- Easy-35 (2.08G, 35 sequences, tested in CVPR’19) | Baidu Pan(fetch code: v5ss) | Google Drive (Updated link: 2021-02-18)
- Normal-25 (1.42G, 25 sequences) | Baidu Pan| Google Drive (Updated link: 2021-02-18)
- Difficult-20 (1.38G, 20 sequences) | Baidu Pan | Google Drive (Updated link: 2021-02-18)
- video description, name, attributes: DAVSOD-name.xlsx (old version) | DAVSOD-name-v2.xlsx ( Updated: 2019-9-11) | DAVSOD-Statistics.xlsx (old version) | DAVSOD-Statistics-v2.xlsx (Updated: 2019-9-11)
Note:
- The DAVSOD-name-v2.xlsx deleted some description of missing videos (0124、0291、0413、0556). Some video like 0189_1 share with the same attributes with 0189. These shared videos including: 0064_1, 0066_1, 0182_1, 0189_1, 0256_1, 0616_1, 0675_1, 0345_1, 0590_2, 0318_1, 0328_1, 0590_1, 0194_1, 0321_1, 0590_3
- we merge the small sequence of the training set. Thus, there are only 61 sequences which are different from the CVPR 2019 paper (90 training sequences).
-
SSAV model.
- caffe version: https://github.com/DengPingFan/DAVSOD
- pytorch version: coming soon.
- Tensorflow version: coming soon.
-
Popular Existing Datasets.
Previous datasets have different formats, causing laborious data preprocessing when training or testing. Here we unified the format of all the datasets for easier use:
- original images saved as *.jpg format
- original images indexd of zero (e.g., 00000.jpg)
- ground-truth images saved as *.png format
Year Publisher Dataset Clips Download Link1 Download Link2 2010 BMVC SegV1 5(11.9MB) Baidu Pan Google Driver 2013 ICCV SegV2 14(84.9MB) Baidu Pan Google Driver 2014 TPAMI FBMS 30 (790MB) Baidu Pan Google Driver 2014 TPAMI FBMS-59 (overall) 59(817.52MB) Baidu Pan Google Driver 2015 TIP MCL 9(308MB) Baidu Pan Google Driver 2015 TIP ViSal 17(59.1MB) Baidu Pan Google Driver 2016 CVPR DAVIS 50(842MB) Baidu Pan Google Driver 2017 TCSVT UVSD 18(207MB) Baidu Pan Google Driver 2018 TIP VOS 200(3.33GB) Baidu Pan Google Driver VOS_test 40(672MB) Baidu Pan Google Driver 2019 CVPR DAVSOD 187(10.24G) Baidu Pan (fetch code: ivzo) Google Driver All datasets Google Driver * We do not include the “penguin sequence” of the SegTrack-V2 dataset due to its inaccurate segmentation. Thus the results of the MCL dataset only contains 13 sequences in our benchmark. For VOS dataset, we only benchmark the test sequence divided by our benchmark (Traning Set: Val Set: Test Set = 6:2:2).
-
Papers & Codes & Results (continue updating).
We have spent about half a year to execute all of the codes. You can download all the results directly for the convience of research. Please cite our paper if you use our results. The overall results link is here (Baidu|Google) (Update: 2019-11-17)
| Year & Pub & Paper | Model | DAVIS | FBMS | MCL | SegV1 | SegV2 | UVSD | ViSal | VOS | DAVSOD & Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| 2008 & CVPR & PQFT | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2009 & JOV & SST | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2010 & ECCV & SIVM | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2014 & CVPR & TIMP | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2014 & TCSVT & SPVM | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2015 & CVPR & SAG | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2015 & TIP & GFVM | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2015 & TIP & RWRV | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2015 & ICCV & MB+ | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2016 & CVPR & MST | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2017 & TCSVT & SGSP | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2017 & TIP & SFLR | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2017 & TIP & STBP | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2017 & TCYB & VSOP | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2017 & BMVC & DSR3D | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & TIP & STCRF | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & TIP & SCOM | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & TIP & DLVSD | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & TCSVT & SCNN | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & ECCV & MBNM | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & ECCV & PDB | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2018 & CVPR & FGRNE | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
| 2019 & CVPR & SSAV | Code | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google | Baidu | Google |
The code has been tested successfully on Ubuntu 16.04 with CUDA 8.0 and OpenCV 3.1.0
-
Prerequisites:
Use
DAVSOD/mycaffe-convlstm/Makefile.configto build caffe. Follow official instructions.make all -j8 make pycaffe
-
Downloading necessary data:
-
downloading the training/testing dataset and move it into
Datasets/. -
downloading pre-trained caffemodel and move it into
model/, which can be found in baidu pan(Fetch Code: pb0h) | google drive.
-
-
Testing Configuration:
-
After you download the pre-trained model and testing dataset, just run
generateTestList.pyto get the test list, andSSAV_test.pyto get the saliency maps inresults/SSAV/. -
Just enjoy it!
-
The prediction results of all competitors and our PNS-Net can be found at Google Drive (7MB).
-
-
Training Configuration:
- With the training dataset downloaded, you can download the basemodel from baidu pan (Fetch Code:0xk4) | google drive.
-
Evaluating model:
- One-key evaluation is written in MATLAB code
main.minDAVSOD/EvaluateTool/. Details of the evaluation metrics please refer to the following papers.[1]Structure-measure: A New Way to Evaluate the Foregournd Maps, ICCV2017. [2]Enhanced Alignment Measure for Binary Foreground Map Evaluation, IJCAI2018.
- One-key evaluation is written in MATLAB code
Note that: This version only provide the implicit manner for learning attention-shift. The explicit way to train this model will not be released due to the commercial purposes (Hua Wei, IIAI).
-
Leaderboard.

Figure 4: Summarizing of 36 previous representative VSOD methods and the proposed SSAV model. -
Benchmark.

Figure 5: Benchmarking results of 17 state-of-the-art VSOD models on 7 datasets. -
Performance Preview



Figure 6: Blackswan sequence result generated by our SSAV model. More results can be found in supplemental materials. -
DAVSOD Dataset Profile

Figure 7: Samples from our dataset, with instance-level ground truth segmentation and fixation map.
Figure 8: Examples to show our rigorous standards for segmentation labeling.
Figure 9: Example sequence of saliency shift considered in the proposed DAVSOD dataset. Different (5th row) from tradition work which labels all the salient objects (2th row) via static frames. The proposed DAVSOD dataset were strictly annotated according to real human fixation record (3rd row), thus revealing the dynamic human attention mechanism.Watch the video for Supplemental Material








If you find this useful, please cite the following works:
@InProceedings{Fan_2019_CVPR,
author = {Fan, Deng-Ping and Wang, Wenguan and Cheng, Ming-Ming and Shen, Jianbing},
title = {Shifting More Attention to Video Salient Object Detection},
booktitle = {IEEE CVPR},
year = {2019}
}
@inproceedings{song2018pyramid,
title={Pyramid dilated deeper ConvLSTM for video salient object detection},
author={Song, Hongmei and Wang, Wenguan and Zhao, Sanyuan and Shen, Jianbing and Lam, Kin-Man},
booktitle={ECCV},
pages={715--731},
year={2018}
}
Contact: Deng-Ping Fan ([email protected]).