+
+ | Model |
+ Config |
+ Metric |
+ PyTorch |
+ ONNX Runtime |
+ TensorRT |
+
+
+ | FCOS |
+ configs/fcos/fcos_r50_caffe_fpn_gn-head_4x4_1x_coco.py |
+ Box AP |
+ 36.6 |
+ 36.5 |
+ 36.3 |
+
+
+ | FSAF |
+ configs/fsaf/fsaf_r50_fpn_1x_coco.py |
+ Box AP |
+ 36.0 |
+ 36.0 |
+ 35.9 |
+
+
+ | RetinaNet |
+ configs/retinanet/retinanet_r50_fpn_1x_coco.py |
+ Box AP |
+ 36.5 |
+ 36.4 |
+ 36.3 |
+
+
+ | SSD |
+ configs/ssd/ssd300_coco.py |
+ Box AP |
+ 25.6 |
+ 25.6 |
+ 25.6 |
+
+
+ | YOLOv3 |
+ configs/yolo/yolov3_d53_mstrain-608_273e_coco.py |
+ Box AP |
+ 33.5 |
+ 33.5 |
+ 33.5 |
+
+
+ | Faster R-CNN |
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py |
+ Box AP |
+ 37.4 |
+ 37.4 |
+ 37.0 |
+
+
+ | Cascade R-CNN |
+ configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py |
+ Box AP |
+ 40.3 |
+ 40.3 |
+ 40.1 |
+
+
+
+ | Mask R-CNN |
+ configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py |
+ Box AP |
+ 38.2 |
+ 38.1 |
+ 37.7 |
+
+
+ | Mask AP |
+ 34.7 |
+ 33.7 |
+ 33.3 |
+
+
+ | Cascade Mask R-CNN |
+ configs/cascade_rcnn/cascade_mask_rcnn_r50_fpn_1x_coco.py |
+ Box AP |
+ 41.2 |
+ 41.2 |
+ 40.9 |
+
+
+ | Mask AP |
+ 35.9 |
+ 34.8 |
+ 34.5 |
+
+
+
+ | CornerNet |
+ configs/cornernet/cornernet_hourglass104_mstest_10x5_210e_coco.py |
+ Box AP |
+ 40.6 |
+ 40.4 |
+ - |
+
+
+ | DETR |
+ configs/detr/detr_r50_8x2_150e_coco.py |
+ Box AP |
+ 40.1 |
+ 40.1 |
+ - |
+
+
+ | PointRend |
+ configs/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco.py |
+ Box AP |
+ 38.4 |
+ 38.4 |
+ - |
+
+
+ | Mask AP |
+ 36.3 |
+ 35.2 |
+ - |
+
+
+
+Notes:
+
+- All ONNX models are evaluated with dynamic shape on coco dataset and images are preprocessed according to the original config file. Note that CornerNet is evaluated without test-time flip, since currently only single-scale evaluation is supported with ONNX Runtime.
+
+- Mask AP of Mask R-CNN drops by 1% for ONNXRuntime. The main reason is that the predicted masks are directly interpolated to original image in PyTorch, while they are at first interpolated to the preprocessed input image of the model and then to original image in other backend.
+
+## List of supported models exportable to ONNX
+
+The table below lists the models that are guaranteed to be exportable to ONNX and runnable in ONNX Runtime.
+
+| Model | Config | Dynamic Shape | Batch Inference | Note |
+| :----------------: | :-----------------------------------------------------------------: | :-----------: | :-------------: | :---------------------------------------------------------------------------: |
+| FCOS | `configs/fcos/fcos_r50_caffe_fpn_gn-head_4x4_1x_coco.py` | Y | Y | |
+| FSAF | `configs/fsaf/fsaf_r50_fpn_1x_coco.py` | Y | Y | |
+| RetinaNet | `configs/retinanet/retinanet_r50_fpn_1x_coco.py` | Y | Y | |
+| SSD | `configs/ssd/ssd300_coco.py` | Y | Y | |
+| YOLOv3 | `configs/yolo/yolov3_d53_mstrain-608_273e_coco.py` | Y | Y | |
+| Faster R-CNN | `configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py` | Y | Y | |
+| Cascade R-CNN | `configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py` | Y | Y | |
+| Mask R-CNN | `configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py` | Y | Y | |
+| Cascade Mask R-CNN | `configs/cascade_rcnn/cascade_mask_rcnn_r50_fpn_1x_coco.py` | Y | Y | |
+| CornerNet | `configs/cornernet/cornernet_hourglass104_mstest_10x5_210e_coco.py` | Y | N | no flip, no batch inference, tested with torch==1.7.0 and onnxruntime==1.5.1. |
+| DETR | `configs/detr/detr_r50_8x2_150e_coco.py` | Y | Y | batch inference is *not recommended* |
+| PointRend | `configs/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco.py` | Y | Y | |
+
+Notes:
+
+- Minimum required version of MMCV is `1.3.5`
+
+- *All models above are tested with Pytorch==1.6.0 and onnxruntime==1.5.1*, except for CornerNet. For more details about the
+ torch version when exporting CornerNet to ONNX, which involves `mmcv::cummax`, please refer to the [Known Issues](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/onnxruntime_op.md#known-issues) in mmcv.
+
+- Though supported, it is *not recommended* to use batch inference in onnxruntime for `DETR`, because there is huge performance gap between ONNX and torch model (e.g. 33.5 vs 39.9 mAP on COCO for onnxruntime and torch respectively, with a batch size 2). The main reason for the gap is that these is non-negligible effect on the predicted regressions during batch inference for ONNX, since the predicted coordinates is normalized by `img_shape` (without padding) and should be converted to absolute format, but `img_shape` is not dynamically traceable thus the padded `img_shape_for_onnx` is used.
+
+- Currently only single-scale evaluation is supported with ONNX Runtime, also `mmcv::SoftNonMaxSuppression` is only supported for single image by now.
+
+## The Parameters of Non-Maximum Suppression in ONNX Export
+
+In the process of exporting the ONNX model, we set some parameters for the NMS op to control the number of output bounding boxes. The following will introduce the parameter setting of the NMS op in the supported models. You can set these parameters through `--cfg-options`.
+
+- `nms_pre`: The number of boxes before NMS. The default setting is `1000`.
+
+- `deploy_nms_pre`: The number of boxes before NMS when exporting to ONNX model. The default setting is `0`.
+
+- `max_per_img`: The number of boxes to be kept after NMS. The default setting is `100`.
+
+- `max_output_boxes_per_class`: Maximum number of output boxes per class of NMS. The default setting is `200`.
+
+## Reminders
+
+- When the input model has custom op such as `RoIAlign` and if you want to verify the exported ONNX model, you may have to build `mmcv` with [ONNXRuntime](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) from source.
+- `mmcv.onnx.simplify` feature is based on [onnx-simplifier](https://github.com/daquexian/onnx-simplifier). If you want to try it, please refer to [onnx in `mmcv`](https://mmcv.readthedocs.io/en/latest/deployment/onnx.html) and [onnxruntime op in `mmcv`](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) for more information.
+- If you meet any problem with the listed models above, please create an issue and it would be taken care of soon. For models not included in the list, please try to dig a little deeper and debug a little bit more and hopefully solve them by yourself.
+- Because this feature is experimental and may change fast, please always try with the latest `mmcv` and `mmdetecion`.
+
+## FAQs
+
+- None
diff --git a/downstream/mmdetection/docs/en/tutorials/test_results_submission.md b/downstream/mmdetection/docs/en/tutorials/test_results_submission.md
new file mode 100644
index 0000000..aed595c
--- /dev/null
+++ b/downstream/mmdetection/docs/en/tutorials/test_results_submission.md
@@ -0,0 +1,112 @@
+# Tutorial 12: Test Results Submission
+
+## Panoptic segmentation test results submission
+
+The following sections introduce how to produce the prediction results of panoptic segmentation models on the COCO test-dev set and submit the predictions to [COCO evaluation server](https://competitions.codalab.org/competitions/19507).
+
+### Prerequisites
+
+- Download [COCO test dataset images](http://images.cocodataset.org/zips/test2017.zip), [testing image info](http://images.cocodataset.org/annotations/image_info_test2017.zip), and [panoptic train/val annotations](http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip), then unzip them, put 'test2017' to `data/coco/`, put json files and annotation files to `data/coco/annotations/`.
+
+```shell
+# suppose data/coco/ does not exist
+mkdir -pv data/coco/
+
+# download test2017
+wget -P data/coco/ http://images.cocodataset.org/zips/test2017.zip
+wget -P data/coco/ http://images.cocodataset.org/annotations/image_info_test2017.zip
+wget -P data/coco/ http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip
+
+# unzip them
+unzip data/coco/test2017.zip -d data/coco/
+unzip data/coco/image_info_test2017.zip -d data/coco/
+unzip data/coco/panoptic_annotations_trainval2017.zip -d data/coco/
+
+# remove zip files (optional)
+rm -rf data/coco/test2017.zip data/coco/image_info_test2017.zip data/coco/panoptic_annotations_trainval2017.zip
+```
+
+- Run the following code to update category information in testing image info. Since the attribute `isthing` is missing in category information of 'image_info_test-dev2017.json', we need to update it with the category information in 'panoptic_val2017.json'.
+
+```shell
+python tools/misc/gen_coco_panoptic_test_info.py data/coco/annotations
+```
+
+After completing the above preparations, your directory structure of `data` should be like this:
+
+```text
+data
+`-- coco
+ |-- annotations
+ | |-- image_info_test-dev2017.json
+ | |-- image_info_test2017.json
+ | |-- panoptic_image_info_test-dev2017.json
+ | |-- panoptic_train2017.json
+ | |-- panoptic_train2017.zip
+ | |-- panoptic_val2017.json
+ | `-- panoptic_val2017.zip
+ `-- test2017
+```
+
+### Inference on coco test-dev
+
+The commands to perform inference on test2017 are as below:
+
+```shell
+# test with single gpu
+CUDA_VISIBLE_DEVICES=0 python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ --format-only \
+ --cfg-options data.test.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json data.test.img_prefix=data/coco/test2017 \
+ --eval-options jsonfile_prefix=${WORK_DIR}/results
+
+# test with four gpus
+CUDA_VISIBLE_DEVICES=0,1,3,4 bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ 4 \ # four gpus
+ --format-only \
+ --cfg-options data.test.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json data.test.img_prefix=data/coco/test2017 \
+ --eval-options jsonfile_prefix=${WORK_DIR}/results
+
+# test with slurm
+GPUS=8 tools/slurm_test.sh \
+ ${Partition} \
+ ${JOB_NAME} \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ --format-only \
+ --cfg-options data.test.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json data.test.img_prefix=data/coco/test2017 \
+ --eval-options jsonfile_prefix=${WORK_DIR}/results
+```
+
+Example
+
+Suppose we perform inference on `test2017` using pretrained MaskFormer with ResNet-50 backbone.
+
+```shell
+# test with single gpu
+CUDA_VISIBLE_DEVICES=0 python tools/test.py \
+ configs/maskformer/maskformer_r50_mstrain_16x1_75e_coco.py \
+ checkpoints/maskformer_r50_mstrain_16x1_75e_coco_20220221_141956-bc2699cb.pth \
+ --format-only \
+ --cfg-options data.test.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json data.test.img_prefix=data/coco/test2017 \
+ --eval-options jsonfile_prefix=work_dirs/maskformer/results
+```
+
+### Rename files and zip results
+
+After inference, the panoptic segmentation results (a json file and a directory where the masks are stored) will be in `WORK_DIR`. We should rename them according to the naming convention described on [COCO's Website](https://cocodataset.org/#upload). Finally, we need to compress the json and the directory where the masks are stored into a zip file, and rename the zip file according to the naming convention. Note that the zip file should **directly** contains the above two files.
+
+The commands to rename files and zip results:
+
+```shell
+# In WORK_DIR, we have panoptic segmentation results: 'panoptic' and 'results.panoptic.json'.
+cd ${WORK_DIR}
+
+# replace '[algorithm_name]' with the name of algorithm you used.
+mv ./panoptic ./panoptic_test-dev2017_[algorithm_name]_results
+mv ./results.panoptic.json ./panoptic_test-dev2017_[algorithm_name]_results.json
+zip panoptic_test-dev2017_[algorithm_name]_results.zip -ur panoptic_test-dev2017_[algorithm_name]_results panoptic_test-dev2017_[algorithm_name]_results.json
+```
diff --git a/downstream/mmdetection/docs/en/tutorials/useful_hooks.md b/downstream/mmdetection/docs/en/tutorials/useful_hooks.md
new file mode 100644
index 0000000..f84be97
--- /dev/null
+++ b/downstream/mmdetection/docs/en/tutorials/useful_hooks.md
@@ -0,0 +1,83 @@
+# Tutorial 13: Useful Hooks
+
+MMDetection and MMCV provide users with various useful hooks including log hooks, evaluation hooks, NumClassCheckHook, etc. This tutorial introduces the functionalities and usages of hooks implemented in MMDetection. For using hooks in MMCV, please read the [API documentation in MMCV](https://github.com/open-mmlab/mmcv/blob/master/docs/en/understand_mmcv/runner.md).
+
+## CheckInvalidLossHook
+
+## EvalHook and DistEvalHook
+
+## ExpMomentumEMAHook and LinearMomentumEMAHook
+
+## NumClassCheckHook
+
+## [MemoryProfilerHook](https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/hook/memory_profiler_hook.py)
+
+Memory profiler hook records memory information including virtual memory, swap memory, and the memory of the current process. This hook helps grasp the memory usage of the system and discover potential memory leak bugs. To use this hook, users should install `memory_profiler` and `psutil` by `pip install memory_profiler psutil` first.
+
+### Usage
+
+To use this hook, users should add the following code to the config file.
+
+```python
+custom_hooks = [
+ dict(type='MemoryProfilerHook', interval=50)
+]
+```
+
+### Result
+
+During training, you can see the messages in the log recorded by `MemoryProfilerHook` as below. The system has 250 GB (246360 MB + 9407 MB) of memory and 8 GB (5740 MB + 2452 MB) of swap memory in total. Currently 9407 MB (4.4%) of memory and 5740 MB (29.9%) of swap memory were consumed. And the current training process consumed 5434 MB of memory.
+
+```text
+2022-04-21 08:49:56,881 - mmdet - INFO - Memory information available_memory: 246360 MB, used_memory: 9407 MB, memory_utilization: 4.4 %, available_swap_memory: 5740 MB, used_swap_memory: 2452 MB, swap_memory_utilization: 29.9 %, current_process_memory: 5434 MB
+```
+
+## SetEpochInfoHook
+
+## SyncNormHook
+
+## SyncRandomSizeHook
+
+## YOLOXLrUpdaterHook
+
+## YOLOXModeSwitchHook
+
+## How to implement a custom hook
+
+In general, there are 10 points where hooks can be inserted from the beginning to the end of model training. The users can implement custom hooks and insert them at different points in the process of training to do what they want.
+
+- global points: `before_run`, `after_run`
+- points in training: `before_train_epoch`, `before_train_iter`, `after_train_iter`, `after_train_epoch`
+- points in validation: `before_val_epoch`, `before_val_iter`, `after_val_iter`, `after_val_epoch`
+
+For example, users can implement a hook to check loss and terminate training when loss goes NaN. To achieve that, there are three steps to go:
+
+1. Implement a new hook that inherits the `Hook` class in MMCV, and implement `after_train_iter` method which checks whether loss goes NaN after every `n` training iterations.
+2. The implemented hook should be registered in `HOOKS` by `@HOOKS.register_module()` as shown in the code below.
+3. Add `custom_hooks = [dict(type='MemoryProfilerHook', interval=50)]` in the config file.
+
+```python
+import torch
+from mmcv.runner.hooks import HOOKS, Hook
+
+
+@HOOKS.register_module()
+class CheckInvalidLossHook(Hook):
+ """Check invalid loss hook.
+ This hook will regularly check whether the loss is valid
+ during training.
+ Args:
+ interval (int): Checking interval (every k iterations).
+ Default: 50.
+ """
+
+ def __init__(self, interval=50):
+ self.interval = interval
+
+ def after_train_iter(self, runner):
+ if self.every_n_iters(runner, self.interval):
+ assert torch.isfinite(runner.outputs['loss']), \
+ runner.logger.info('loss become infinite or NaN!')
+```
+
+Please read [customize_runtime](https://mmdetection.readthedocs.io/en/latest/tutorials/customize_runtime.html#customize-self-implemented-hooks) for more about implementing a custom hook.
diff --git a/downstream/mmdetection/docs/en/useful_tools.md b/downstream/mmdetection/docs/en/useful_tools.md
new file mode 100644
index 0000000..8e5c49d
--- /dev/null
+++ b/downstream/mmdetection/docs/en/useful_tools.md
@@ -0,0 +1,502 @@
+Apart from training/testing scripts, We provide lots of useful tools under the
+`tools/` directory.
+
+## Log Analysis
+
+`tools/analysis_tools/analyze_logs.py` plots loss/mAP curves given a training
+log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--eval-interval ${EVALUATION_INTERVAL}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
+ ```
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
+ ```
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
+ ```
+
+- Compute the average training speed.
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
+ ```
+
+ The output is expected to be like the following.
+
+ ```text
+ -----Analyze train time of work_dirs/some_exp/20190611_192040.log.json-----
+ slowest epoch 11, average time is 1.2024
+ fastest epoch 1, average time is 1.1909
+ time std over epochs is 0.0028
+ average iter time: 1.1959 s/iter
+ ```
+
+## Result Analysis
+
+`tools/analysis_tools/analyze_results.py` calculates single image mAP and saves or shows the topk images with the highest and lowest scores based on prediction results.
+
+**Usage**
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ ${CONFIG} \
+ ${PREDICTION_PATH} \
+ ${SHOW_DIR} \
+ [--show] \
+ [--wait-time ${WAIT_TIME}] \
+ [--topk ${TOPK}] \
+ [--show-score-thr ${SHOW_SCORE_THR}] \
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+Description of all arguments:
+
+- `config` : The path of a model config file.
+- `prediction_path`: Output result file in pickle format from `tools/test.py`
+- `show_dir`: Directory where painted GT and detection images will be saved
+- `--show`:Determines whether to show painted images, If not specified, it will be set to `False`
+- `--wait-time`: The interval of show (s), 0 is block
+- `--topk`: The number of saved images that have the highest and lowest `topk` scores after sorting. If not specified, it will be set to `20`.
+- `--show-score-thr`: Show score threshold. If not specified, it will be set to `0`.
+- `--cfg-options`: If specified, the key-value pair optional cfg will be merged into config file
+
+**Examples**:
+
+Assume that you have got result file in pickle format from `tools/test.py` in the path './result.pkl'.
+
+1. Test Faster R-CNN and visualize the results, save images to the directory `results/`
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ result.pkl \
+ results \
+ --show
+```
+
+2. Test Faster R-CNN and specified topk to 50, save images to the directory `results/`
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ result.pkl \
+ results \
+ --topk 50
+```
+
+3. If you want to filter the low score prediction results, you can specify the `show-score-thr` parameter
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ result.pkl \
+ results \
+ --show-score-thr 0.3
+```
+
+## Visualization
+
+### Visualize Datasets
+
+`tools/misc/browse_dataset.py` helps the user to browse a detection dataset (both
+images and bounding box annotations) visually, or save the image to a
+designated directory.
+
+```shell
+python tools/misc/browse_dataset.py ${CONFIG} [-h] [--skip-type ${SKIP_TYPE[SKIP_TYPE...]}] [--output-dir ${OUTPUT_DIR}] [--not-show] [--show-interval ${SHOW_INTERVAL}]
+```
+
+### Visualize Models
+
+First, convert the model to ONNX as described
+[here](#convert-mmdetection-model-to-onnx-experimental).
+Note that currently only RetinaNet is supported, support for other models
+will be coming in later versions.
+The converted model could be visualized by tools like [Netron](https://github.com/lutzroeder/netron).
+
+### Visualize Predictions
+
+If you need a lightweight GUI for visualizing the detection results, you can refer [DetVisGUI project](https://github.com/Chien-Hung/DetVisGUI/tree/mmdetection).
+
+## Error Analysis
+
+`tools/analysis_tools/coco_error_analysis.py` analyzes COCO results per category and by
+different criterion. It can also make a plot to provide useful information.
+
+```shell
+python tools/analysis_tools/coco_error_analysis.py ${RESULT} ${OUT_DIR} [-h] [--ann ${ANN}] [--types ${TYPES[TYPES...]}]
+```
+
+Example:
+
+Assume that you have got [Mask R-CNN checkpoint file](https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_1x_coco/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth) in the path 'checkpoint'. For other checkpoints, please refer to our [model zoo](./model_zoo.md). You can use the following command to get the results bbox and segmentation json file.
+
+```shell
+# out: results.bbox.json and results.segm.json
+python tools/test.py \
+ configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py \
+ checkpoint/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ --format-only \
+ --options "jsonfile_prefix=./results"
+```
+
+1. Get COCO bbox error results per category , save analyze result images to the directory `results/`
+
+```shell
+python tools/analysis_tools/coco_error_analysis.py \
+ results.bbox.json \
+ results \
+ --ann=data/coco/annotations/instances_val2017.json \
+```
+
+2. Get COCO segmentation error results per category , save analyze result images to the directory `results/`
+
+```shell
+python tools/analysis_tools/coco_error_analysis.py \
+ results.segm.json \
+ results \
+ --ann=data/coco/annotations/instances_val2017.json \
+ --types='segm'
+```
+
+## Model Serving
+
+In order to serve an `MMDetection` model with [`TorchServe`](https://pytorch.org/serve/), you can follow the steps:
+
+### 1. Convert model from MMDetection to TorchServe
+
+```shell
+python tools/deployment/mmdet2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+**Note**: ${MODEL_STORE} needs to be an absolute path to a folder.
+
+### 2. Build `mmdet-serve` docker image
+
+```shell
+docker build -t mmdet-serve:latest docker/serve/
+```
+
+### 3. Run `mmdet-serve`
+
+Check the official docs for [running TorchServe with docker](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+In order to run in GPU, you need to install [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). You can omit the `--gpus` argument in order to run in CPU.
+
+Example:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmdet-serve:latest
+```
+
+[Read the docs](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md/) about the Inference (8080), Management (8081) and Metrics (8082) APis
+
+### 4. Test deployment
+
+```shell
+curl -O curl -O https://raw.githubusercontent.com/pytorch/serve/master/docs/images/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg
+```
+
+You should obtain a response similar to:
+
+```json
+[
+ {
+ "class_name": "dog",
+ "bbox": [
+ 294.63409423828125,
+ 203.99111938476562,
+ 417.048583984375,
+ 281.62744140625
+ ],
+ "score": 0.9987992644309998
+ },
+ {
+ "class_name": "dog",
+ "bbox": [
+ 404.26019287109375,
+ 126.0080795288086,
+ 574.5091552734375,
+ 293.6662292480469
+ ],
+ "score": 0.9979367256164551
+ },
+ {
+ "class_name": "dog",
+ "bbox": [
+ 197.2144775390625,
+ 93.3067855834961,
+ 307.8505554199219,
+ 276.7560119628906
+ ],
+ "score": 0.993338406085968
+ }
+]
+```
+
+And you can use `test_torchserver.py` to compare result of torchserver and pytorch, and visualize them.
+
+```shell
+python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}] [--score-thr ${SCORE_THR}]
+```
+
+Example:
+
+```shell
+python tools/deployment/test_torchserver.py \
+demo/demo.jpg \
+configs/yolo/yolov3_d53_320_273e_coco.py \
+checkpoint/yolov3_d53_320_273e_coco-421362b6.pth \
+yolov3
+```
+
+## Model Complexity
+
+`tools/analysis_tools/get_flops.py` is a script adapted from [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) to compute the FLOPs and params of a given model.
+
+```shell
+python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+You will get the results like this.
+
+```text
+==============================
+Input shape: (3, 1280, 800)
+Flops: 239.32 GFLOPs
+Params: 37.74 M
+==============================
+```
+
+**Note**: This tool is still experimental and we do not guarantee that the
+number is absolutely correct. You may well use the result for simple
+comparisons, but double check it before you adopt it in technical reports or papers.
+
+1. FLOPs are related to the input shape while parameters are not. The default
+ input shape is (1, 3, 1280, 800).
+2. Some operators are not counted into FLOPs like GN and custom operators. Refer to [`mmcv.cnn.get_model_complexity_info()`](https://github.com/open-mmlab/mmcv/blob/master/mmcv/cnn/utils/flops_counter.py) for details.
+3. The FLOPs of two-stage detectors is dependent on the number of proposals.
+
+## Model conversion
+
+### MMDetection model to ONNX (experimental)
+
+We provide a script to convert model to [ONNX](https://github.com/onnx/onnx) format. We also support comparing the output results between Pytorch and ONNX model for verification.
+
+```shell
+python tools/deployment/pytorch2onnx.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --output-file ${ONNX_FILE} [--shape ${INPUT_SHAPE} --verify]
+```
+
+**Note**: This tool is still experimental. Some customized operators are not supported for now. For a detailed description of the usage and the list of supported models, please refer to [pytorch2onnx](tutorials/pytorch2onnx.md).
+
+### MMDetection 1.x model to MMDetection 2.x
+
+`tools/model_converters/upgrade_model_version.py` upgrades a previous MMDetection checkpoint
+to the new version. Note that this script is not guaranteed to work as some
+breaking changes are introduced in the new version. It is recommended to
+directly use the new checkpoints.
+
+```shell
+python tools/model_converters/upgrade_model_version.py ${IN_FILE} ${OUT_FILE} [-h] [--num-classes NUM_CLASSES]
+```
+
+### RegNet model to MMDetection
+
+`tools/model_converters/regnet2mmdet.py` convert keys in pycls pretrained RegNet models to
+MMDetection style.
+
+```shell
+python tools/model_converters/regnet2mmdet.py ${SRC} ${DST} [-h]
+```
+
+### Detectron ResNet to Pytorch
+
+`tools/model_converters/detectron2pytorch.py` converts keys in the original detectron pretrained
+ResNet models to PyTorch style.
+
+```shell
+python tools/model_converters/detectron2pytorch.py ${SRC} ${DST} ${DEPTH} [-h]
+```
+
+### Prepare a model for publishing
+
+`tools/model_converters/publish_model.py` helps users to prepare their model for publishing.
+
+Before you upload a model to AWS, you may want to
+
+1. convert model weights to CPU tensors
+2. delete the optimizer states and
+3. compute the hash of the checkpoint file and append the hash id to the
+ filename.
+
+```shell
+python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+E.g.,
+
+```shell
+python tools/model_converters/publish_model.py work_dirs/faster_rcnn/latest.pth faster_rcnn_r50_fpn_1x_20190801.pth
+```
+
+The final output filename will be `faster_rcnn_r50_fpn_1x_20190801-{hash id}.pth`.
+
+## Dataset Conversion
+
+`tools/data_converters/` contains tools to convert the Cityscapes dataset
+and Pascal VOC dataset to the COCO format.
+
+```shell
+python tools/dataset_converters/cityscapes.py ${CITYSCAPES_PATH} [-h] [--img-dir ${IMG_DIR}] [--gt-dir ${GT_DIR}] [-o ${OUT_DIR}] [--nproc ${NPROC}]
+python tools/dataset_converters/pascal_voc.py ${DEVKIT_PATH} [-h] [-o ${OUT_DIR}]
+```
+
+## Dataset Download
+
+`tools/misc/download_dataset.py` supports downloading datasets such as COCO, VOC, and LVIS.
+
+```shell
+python tools/misc/download_dataset.py --dataset-name coco2017
+python tools/misc/download_dataset.py --dataset-name voc2007
+python tools/misc/download_dataset.py --dataset-name lvis
+```
+
+## Benchmark
+
+### Robust Detection Benchmark
+
+`tools/analysis_tools/test_robustness.py` and`tools/analysis_tools/robustness_eval.py` helps users to evaluate model robustness. The core idea comes from [Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming](https://arxiv.org/abs/1907.07484). For more information how to evaluate models on corrupted images and results for a set of standard models please refer to [robustness_benchmarking.md](robustness_benchmarking.md).
+
+### FPS Benchmark
+
+`tools/analysis_tools/benchmark.py` helps users to calculate FPS. The FPS value includes model forward and post-processing. In order to get a more accurate value, currently only supports single GPU distributed startup mode.
+
+```shell
+python -m torch.distributed.launch --nproc_per_node=1 --master_port=${PORT} tools/analysis_tools/benchmark.py \
+ ${CONFIG} \
+ ${CHECKPOINT} \
+ [--repeat-num ${REPEAT_NUM}] \
+ [--max-iter ${MAX_ITER}] \
+ [--log-interval ${LOG_INTERVAL}] \
+ --launcher pytorch
+```
+
+Examples: Assuming that you have already downloaded the `Faster R-CNN` model checkpoint to the directory `checkpoints/`.
+
+```shell
+python -m torch.distributed.launch --nproc_per_node=1 --master_port=29500 tools/analysis_tools/benchmark.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --launcher pytorch
+```
+
+## Miscellaneous
+
+### Evaluating a metric
+
+`tools/analysis_tools/eval_metric.py` evaluates certain metrics of a pkl result file
+according to a config file.
+
+```shell
+python tools/analysis_tools/eval_metric.py ${CONFIG} ${PKL_RESULTS} [-h] [--format-only] [--eval ${EVAL[EVAL ...]}]
+ [--cfg-options ${CFG_OPTIONS [CFG_OPTIONS ...]}]
+ [--eval-options ${EVAL_OPTIONS [EVAL_OPTIONS ...]}]
+```
+
+### Print the entire config
+
+`tools/misc/print_config.py` prints the whole config verbatim, expanding all its
+imports.
+
+```shell
+python tools/misc/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
+```
+
+## Hyper-parameter Optimization
+
+### YOLO Anchor Optimization
+
+`tools/analysis_tools/optimize_anchors.py` provides two method to optimize YOLO anchors.
+
+One is k-means anchor cluster which refers from [darknet](https://github.com/AlexeyAB/darknet/blob/master/src/detector.c#L1421).
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm k-means --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
+```
+
+Another is using differential evolution to optimize anchors.
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm differential_evolution --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
+```
+
+E.g.,
+
+```shell
+python tools/analysis_tools/optimize_anchors.py configs/yolo/yolov3_d53_320_273e_coco.py --algorithm differential_evolution --input-shape 608 608 --device cuda --output-dir work_dirs
+```
+
+You will get:
+
+```
+loading annotations into memory...
+Done (t=9.70s)
+creating index...
+index created!
+2021-07-19 19:37:20,951 - mmdet - INFO - Collecting bboxes from annotation...
+[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 117266/117266, 15874.5 task/s, elapsed: 7s, ETA: 0s
+
+2021-07-19 19:37:28,753 - mmdet - INFO - Collected 849902 bboxes.
+differential_evolution step 1: f(x)= 0.506055
+differential_evolution step 2: f(x)= 0.506055
+......
+
+differential_evolution step 489: f(x)= 0.386625
+2021-07-19 19:46:40,775 - mmdet - INFO Anchor evolution finish. Average IOU: 0.6133754253387451
+2021-07-19 19:46:40,776 - mmdet - INFO Anchor differential evolution result:[[10, 12], [15, 30], [32, 22], [29, 59], [61, 46], [57, 116], [112, 89], [154, 198], [349, 336]]
+2021-07-19 19:46:40,798 - mmdet - INFO Result saved in work_dirs/anchor_optimize_result.json
+```
+
+## Confusion Matrix
+
+A confusion matrix is a summary of prediction results.
+
+`tools/analysis_tools/confusion_matrix.py` can analyze the prediction results and plot a confusion matrix table.
+
+First, run `tools/test.py` to save the `.pkl` detection results.
+
+Then, run
+
+```
+python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} --show
+```
+
+And you will get a confusion matrix like this:
+
+
diff --git a/downstream/mmdetection/docs/zh_cn/1_exist_data_model.md b/downstream/mmdetection/docs/zh_cn/1_exist_data_model.md
new file mode 100644
index 0000000..e349343
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/1_exist_data_model.md
@@ -0,0 +1,678 @@
+# 1: 使用已有模型在标准数据集上进行推理
+
+MMDetection 在 [Model Zoo](https://mmdetection.readthedocs.io/en/latest/model_zoo.html) 中提供了数以百计的检测模型,并支持多种标准数据集,包括 Pascal VOC,COCO,Cityscapes,LVIS 等。这份文档将会讲述如何使用这些模型和标准数据集来运行一些常见的任务,包括:
+
+- 使用现有模型在给定图片上进行推理
+- 在标准数据集上测试现有模型
+- 在标准数据集上训练预定义的模型
+
+## 使用现有模型进行推理
+
+推理是指使用训练好的模型来检测图像上的目标。在 MMDetection 中,一个模型被定义为一个配置文件和对应的存储在 checkpoint 文件内的模型参数的集合。
+
+首先,我们建议从 [Faster RCNN](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) 开始,其 [配置](https://github.com/open-mmlab/mmdetection/blob/master/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py) 文件和 [checkpoint](http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth) 文件在此。
+我们建议将 checkpoint 文件下载到 `checkpoints` 文件夹内。
+
+### 推理的高层编程接口
+
+MMDetection 为在图片上推理提供了 Python 的高层编程接口。下面是建立模型和在图像或视频上进行推理的例子。
+
+```python
+from mmdet.apis import init_detector, inference_detector
+import mmcv
+
+# 指定模型的配置文件和 checkpoint 文件路径
+config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
+checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
+
+# 根据配置文件和 checkpoint 文件构建模型
+model = init_detector(config_file, checkpoint_file, device='cuda:0')
+
+# 测试单张图片并展示结果
+img = 'test.jpg' # 或者 img = mmcv.imread(img),这样图片仅会被读一次
+result = inference_detector(model, img)
+# 在一个新的窗口中将结果可视化
+model.show_result(img, result)
+# 或者将可视化结果保存为图片
+model.show_result(img, result, out_file='result.jpg')
+
+# 测试视频并展示结果
+video = mmcv.VideoReader('video.mp4')
+for frame in video:
+ result = inference_detector(model, frame)
+ model.show_result(frame, result, wait_time=1)
+```
+
+jupyter notebook 上的演示样例在 [demo/inference_demo.ipynb](https://github.com/open-mmlab/mmdetection/blob/master/demo/inference_demo.ipynb) 。
+
+### 异步接口-支持 Python 3.7+
+
+对于 Python 3.7+,MMDetection 也有异步接口。利用 CUDA 流,绑定 GPU 的推理代码不会阻塞 CPU,从而使得 CPU/GPU 在单线程应用中能达到更高的利用率。在推理流程中,不同数据样本的推理和不同模型的推理都能并发地运行。
+
+您可以参考 `tests/async_benchmark.py` 来对比同步接口和异步接口的运行速度。
+
+```python
+import asyncio
+import torch
+from mmdet.apis import init_detector, async_inference_detector
+from mmdet.utils.contextmanagers import concurrent
+
+async def main():
+ config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
+ checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
+ device = 'cuda:0'
+ model = init_detector(config_file, checkpoint=checkpoint_file, device=device)
+
+ # 此队列用于并行推理多张图像
+ streamqueue = asyncio.Queue()
+ # 队列大小定义了并行的数量
+ streamqueue_size = 3
+
+ for _ in range(streamqueue_size):
+ streamqueue.put_nowait(torch.cuda.Stream(device=device))
+
+ # 测试单张图片并展示结果
+ img = 'test.jpg' # or 或者 img = mmcv.imread(img),这样图片仅会被读一次
+
+ async with concurrent(streamqueue):
+ result = await async_inference_detector(model, img)
+
+ # 在一个新的窗口中将结果可视化
+ model.show_result(img, result)
+ # 或者将可视化结果保存为图片
+ model.show_result(img, result, out_file='result.jpg')
+
+
+asyncio.run(main())
+
+```
+
+### 演示样例
+
+我们还提供了三个演示脚本,它们是使用高层编程接口实现的。 [源码在此](https://github.com/open-mmlab/mmdetection/tree/master/demo) 。
+
+#### 图片样例
+
+这是在单张图片上进行推理的脚本,可以开启 `--async-test` 来进行异步推理。
+
+```shell
+python demo/image_demo.py \
+ ${IMAGE_FILE} \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--device ${GPU_ID}] \
+ [--score-thr ${SCORE_THR}] \
+ [--async-test]
+```
+
+运行样例:
+
+```shell
+python demo/image_demo.py demo/demo.jpg \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --device cpu
+```
+
+#### 摄像头样例
+
+这是使用摄像头实时图片的推理脚本。
+
+```shell
+python demo/webcam_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--device ${GPU_ID}] \
+ [--camera-id ${CAMERA-ID}] \
+ [--score-thr ${SCORE_THR}]
+```
+
+运行样例:
+
+```shell
+python demo/webcam_demo.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
+```
+
+#### 视频样例
+
+这是在视频样例上进行推理的脚本。
+
+```shell
+python demo/video_demo.py \
+ ${VIDEO_FILE} \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--device ${GPU_ID}] \
+ [--score-thr ${SCORE_THR}] \
+ [--out ${OUT_FILE}] \
+ [--show] \
+ [--wait-time ${WAIT_TIME}]
+```
+
+运行样例:
+
+```shell
+python demo/video_demo.py demo/demo.mp4 \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --out result.mp4
+```
+
+#### 视频样例,显卡加速版本
+
+这是在视频样例上进行推理的脚本,使用显卡加速。
+
+```shell
+python demo/video_gpuaccel_demo.py \
+ ${VIDEO_FILE} \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--device ${GPU_ID}] \
+ [--score-thr ${SCORE_THR}] \
+ [--nvdecode] \
+ [--out ${OUT_FILE}] \
+ [--show] \
+ [--wait-time ${WAIT_TIME}]
+
+```
+
+运行样例:
+
+```shell
+python demo/video_gpuaccel_demo.py demo/demo.mp4 \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --nvdecode --out result.mp4
+```
+
+## 在标准数据集上测试现有模型
+
+为了测试一个模型的精度,我们通常会在标准数据集上对其进行测试。MMDetection 支持多个公共数据集,包括 [COCO](https://cocodataset.org/) ,
+[Pascal VOC](http://host.robots.ox.ac.uk/pascal/VOC) ,[Cityscapes](https://www.cityscapes-dataset.com/) 等等。
+这一部分将会介绍如何在支持的数据集上测试现有模型。
+
+### 数据集准备
+
+一些公共数据集,比如 Pascal VOC 及其镜像数据集,或者 COCO 等数据集都可以从官方网站或者镜像网站获取。
+注意:在检测任务中,Pascal VOC 2012 是 Pascal VOC 2007 的无交集扩展,我们通常将两者一起使用。
+我们建议将数据集下载,然后解压到项目外部的某个文件夹内,然后通过符号链接的方式,将数据集根目录链接到 `$MMDETECTION/data` 文件夹下,格式如下所示。
+如果你的文件夹结构和下方不同的话,你需要在配置文件中改变对应的路径。
+我们提供了下载 COCO 等数据集的脚本,你可以运行 `python tools/misc/download_dataset.py --dataset-name coco2017` 下载 COCO 数据集。
+
+```plain
+mmdetection
+├── mmdet
+├── tools
+├── configs
+├── data
+│ ├── coco
+│ │ ├── annotations
+│ │ ├── train2017
+│ │ ├── val2017
+│ │ ├── test2017
+│ ├── cityscapes
+│ │ ├── annotations
+│ │ ├── leftImg8bit
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── gtFine
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── VOCdevkit
+│ │ ├── VOC2007
+│ │ ├── VOC2012
+```
+
+有些模型需要额外的 [COCO-stuff](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip) 数据集,比如 HTC,DetectoRS 和 SCNet,你可以下载并解压它们到 `coco` 文件夹下。文件夹会是如下结构:
+
+```plain
+mmdetection
+├── data
+│ ├── coco
+│ │ ├── annotations
+│ │ ├── train2017
+│ │ ├── val2017
+│ │ ├── test2017
+│ │ ├── stuffthingmaps
+```
+
+PanopticFPN 等全景分割模型需要额外的 [COCO Panoptic](http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip) 数据集,你可以下载并解压它们到 `coco/annotations` 文件夹下。文件夹会是如下结构:
+
+```text
+mmdetection
+├── data
+│ ├── coco
+│ │ ├── annotations
+│ │ │ ├── panoptic_train2017.json
+│ │ │ ├── panoptic_train2017
+│ │ │ ├── panoptic_val2017.json
+│ │ │ ├── panoptic_val2017
+│ │ ├── train2017
+│ │ ├── val2017
+│ │ ├── test2017
+```
+
+Cityscape 数据集的标注格式需要转换,以与 COCO 数据集标注格式保持一致,使用 `tools/dataset_converters/cityscapes.py` 来完成转换:
+
+```shell
+pip install cityscapesscripts
+
+python tools/dataset_converters/cityscapes.py \
+ ./data/cityscapes \
+ --nproc 8 \
+ --out-dir ./data/cityscapes/annotations
+```
+
+### 测试现有模型
+
+我们提供了测试脚本,能够测试一个现有模型在所有数据集(COCO,Pascal VOC,Cityscapes 等)上的性能。我们支持在如下环境下测试:
+
+- 单 GPU 测试
+- CPU 测试
+- 单节点多 GPU 测试
+- 多节点测试
+
+根据以上测试环境,选择合适的脚本来执行测试过程。
+
+```shell
+# 单 GPU 测试
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--eval ${EVAL_METRICS}] \
+ [--show]
+
+# CPU 测试:禁用 GPU 并运行单 GPU 测试脚本
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--eval ${EVAL_METRICS}] \
+ [--show]
+
+# 单节点多 GPU 测试
+bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${GPU_NUM} \
+ [--out ${RESULT_FILE}] \
+ [--eval ${EVAL_METRICS}]
+```
+
+`tools/dist_test.sh` 也支持多节点测试,不过需要依赖 PyTorch 的 [启动工具](https://pytorch.org/docs/stable/distributed.html#launch-utility) 。
+
+可选参数:
+
+- `RESULT_FILE`: 结果文件名称,需以 .pkl 形式存储。如果没有声明,则不将结果存储到文件。
+- `EVAL_METRICS`: 需要测试的度量指标。可选值是取决于数据集的,比如 `proposal_fast`,`proposal`,`bbox`,`segm` 是 COCO 数据集的可选值,`mAP`,`recall` 是 Pascal VOC 数据集的可选值。Cityscapes 数据集可以测试 `cityscapes` 和所有 COCO 数据集支持的度量指标。
+- `--show`: 如果开启,检测结果将被绘制在图像上,以一个新窗口的形式展示。它只适用于单 GPU 的测试,是用于调试和可视化的。请确保使用此功能时,你的 GUI 可以在环境中打开。否则,你可能会遇到这么一个错误 `cannot connect to X server`。
+- `--show-dir`: 如果指明,检测结果将会被绘制在图像上并保存到指定目录。它只适用于单 GPU 的测试,是用于调试和可视化的。即使你的环境中没有 GUI,这个选项也可使用。
+- `--show-score-thr`: 如果指明,得分低于此阈值的检测结果将会被移除。
+- `--cfg-options`: 如果指明,这里的键值对将会被合并到配置文件中。
+- `--eval-options`: 如果指明,这里的键值对将会作为字典参数被传入 `dataset.evaluation()` 函数中,仅在测试阶段使用。
+
+### 样例
+
+假设你已经下载了 checkpoint 文件到 `checkpoints/` 文件下了。
+
+1. 测试 Faster R-CNN 并可视化其结果。按任意键继续下张图片的测试。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) 。
+
+ ```shell
+ python tools/test.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --show
+ ```
+
+2. 测试 Faster R-CNN,并为了之后的可视化保存绘制的图像。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) 。
+
+ ```shell
+ python tools/test.py \
+ configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --show-dir faster_rcnn_r50_fpn_1x_results
+ ```
+
+3. 在 Pascal VOC 数据集上测试 Faster R-CNN,不保存测试结果,测试 `mAP`。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/pascal_voc) 。
+
+ ```shell
+ python tools/test.py \
+ configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_voc0712_20200624-c9895d40.pth \
+ --eval mAP
+ ```
+
+4. 使用 8 块 GPU 测试 Mask R-CNN,测试 `bbox` 和 `mAP` 。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) 。
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/mask_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8 \
+ --out results.pkl \
+ --eval bbox segm
+ ```
+
+5. 使用 8 块 GPU 测试 Mask R-CNN,测试**每类**的 `bbox` 和 `mAP`。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) 。
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8 \
+ --out results.pkl \
+ --eval bbox segm \
+ --options "classwise=True"
+ ```
+
+6. 在 COCO test-dev 数据集上,使用 8 块 GPU 测试 Mask R-CNN,并生成 JSON 文件提交到官方评测服务器。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) 。
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8 \
+ --format-only \
+ --options "jsonfile_prefix=./mask_rcnn_test-dev_results"
+ ```
+
+这行命令生成两个 JSON 文件 `mask_rcnn_test-dev_results.bbox.json` 和 `mask_rcnn_test-dev_results.segm.json`。
+
+7. 在 Cityscapes 数据集上,使用 8 块 GPU 测试 Mask R-CNN,生成 txt 和 png 文件,并上传到官方评测服务器。配置文件和 checkpoint 文件 [在此](https://github.com/open-mmlab/mmdetection/tree/master/configs/cityscapes) 。
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/cityscapes/mask_rcnn_r50_fpn_1x_cityscapes.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_cityscapes_20200227-afe51d5a.pth \
+ 8 \
+ --format-only \
+ --options "txtfile_prefix=./mask_rcnn_cityscapes_test_results"
+ ```
+
+生成的 png 和 txt 文件在 `./mask_rcnn_cityscapes_test_results` 文件夹下。
+
+### 不使用 Ground Truth 标注进行测试
+
+MMDetection 支持在不使用 ground-truth 标注的情况下对模型进行测试,这需要用到 `CocoDataset`。如果你的数据集格式不是 COCO 格式的,请将其转化成 COCO 格式。如果你的数据集格式是 VOC 或者 Cityscapes,你可以使用 [tools/dataset_converters](https://github.com/open-mmlab/mmdetection/tree/master/tools/dataset_converters) 内的脚本直接将其转化成 COCO 格式。如果是其他格式,可以使用 [images2coco 脚本](https://github.com/open-mmlab/mmdetection/tree/master/tools/dataset_converters/images2coco.py) 进行转换。
+
+```shell
+python tools/dataset_converters/images2coco.py \
+ ${IMG_PATH} \
+ ${CLASSES} \
+ ${OUT} \
+ [--exclude-extensions]
+```
+
+参数:
+
+- `IMG_PATH`: 图片根路径。
+- `CLASSES`: 类列表文本文件名。文本中每一行存储一个类别。
+- `OUT`: 输出 json 文件名。 默认保存目录和 `IMG_PATH` 在同一级。
+- `exclude-extensions`: 待排除的文件后缀名。
+
+在转换完成后,使用如下命令进行测试
+
+```shell
+# 单 GPU 测试
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ --format-only \
+ --options ${JSONFILE_PREFIX} \
+ [--show]
+
+# CPU 测试:禁用 GPU 并运行单 GPU 测试脚本
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--eval ${EVAL_METRICS}] \
+ [--show]
+
+# 单节点多 GPU 测试
+bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${GPU_NUM} \
+ --format-only \
+ --options ${JSONFILE_PREFIX} \
+ [--show]
+```
+
+假设 [model zoo](https://mmdetection.readthedocs.io/en/latest/modelzoo_statistics.html) 中的 checkpoint 文件被下载到了 `checkpoints/` 文件夹下,
+我们可以使用以下命令,用 8 块 GPU 在 COCO test-dev 数据集上测试 Mask R-CNN,并且生成 JSON 文件。
+
+```sh
+./tools/dist_test.sh \
+ configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8 \
+ -format-only \
+ --options "jsonfile_prefix=./mask_rcnn_test-dev_results"
+```
+
+这行命令生成两个 JSON 文件 `mask_rcnn_test-dev_results.bbox.json` 和 `mask_rcnn_test-dev_results.segm.json`。
+
+### 批量推理
+
+MMDetection 在测试模式下,既支持单张图片的推理,也支持对图像进行批量推理。默认情况下,我们使用单张图片的测试,你可以通过修改测试数据配置文件中的 `samples_per_gpu` 来开启批量测试。
+开启批量推理的配置文件修改方法为:
+
+```shell
+data = dict(train=dict(...), val=dict(...), test=dict(samples_per_gpu=2, ...))
+```
+
+或者你可以通过将 `--cfg-options` 设置为 `--cfg-options data.test.samples_per_gpu=2` 来开启它。
+
+### 弃用 ImageToTensor
+
+在测试模式下,弃用 `ImageToTensor` 流程,取而代之的是 `DefaultFormatBundle`。建议在你的测试数据流程的配置文件中手动替换它,如:
+
+```python
+# (已弃用)使用 ImageToTensor
+pipelines = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', mean=[0, 0, 0], std=[1, 1, 1]),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+ ]
+
+# (建议使用)手动将 ImageToTensor 替换为 DefaultFormatBundle
+pipelines = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', mean=[0, 0, 0], std=[1, 1, 1]),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img']),
+ ])
+ ]
+```
+
+## 在标准数据集上训练预定义的模型
+
+MMDetection 也为训练检测模型提供了开盖即食的工具。本节将展示在标准数据集(比如 COCO)上如何训练一个预定义的模型。
+
+### 数据集
+
+训练需要准备好数据集,细节请参考 [数据集准备](#%E6%95%B0%E6%8D%AE%E9%9B%86%E5%87%86%E5%A4%87) 。
+
+**注意**:
+目前,`configs/cityscapes` 文件夹下的配置文件都是使用 COCO 预训练权值进行初始化的。如果网络连接不可用或者速度很慢,你可以提前下载现存的模型。否则可能在训练的开始会有错误发生。
+
+### 学习率自动缩放
+
+**注意**:在配置文件中的学习率是在 8 块 GPU,每块 GPU 有 2 张图像(批大小为 8\*2=16)的情况下设置的。其已经设置在`config/_base_/default_runtime.py` 中的 `auto_scale_lr.base_batch_size`。当配置文件的批次大小为`16`时,学习率会基于该值进行自动缩放。同时,为了不影响其他基于 mmdet 的 codebase,启用自动缩放标志 `auto_scale_lr.enable` 默认设置为 `False`。
+
+如果要启用此功能,需在命令添加参数 `--auto-scale-lr`。并且在启动命令之前,请检查下即将使用的配置文件的名称,因为配置名称指示默认的批处理大小。
+在默认情况下,批次大小是 `8 x 2 = 16`,例如:`faster_rcnn_r50_caffe_fpn_90k_coco.py` 或者 `pisa_faster_rcnn_x101_32x4d_fpn_1x_coco.py`;若不是默认批次,你可以在配置文件看到像 `_NxM_` 字样的,例如:`cornernet_hourglass104_mstest_32x3_210e_coco.py` 的批次大小是 `32 x 3 = 96`, 或者 `scnet_x101_64x4d_fpn_8x1_20e_coco.py` 的批次大小是 `8 x 1 = 8`。
+
+**请记住:如果使用不是默认批次大小为`16`的配置文件,请检查配置文件中的底部,会有 `auto_scale_lr.base_batch_size`。如果找不到,可以在其继承的 `_base_=[xxx]` 文件中找到。另外,如果想使用自动缩放学习率的功能,请不要修改这些值。**
+
+学习率自动缩放基本用法如下:
+
+```shell
+python tools/train.py \
+ ${CONFIG_FILE} \
+ --auto-scale-lr \
+ [optional arguments]
+```
+
+执行命令之后,会根据机器的GPU数量和训练的批次大小对学习率进行自动缩放,缩放方式详见 [线性扩展规则](https://arxiv.org/abs/1706.02677) ,比如:在 4 块 GPU 并且每张 GPU 上有 2 张图片的情况下 `lr=0.01`,那么在 16 块 GPU 并且每张 GPU 上有 4 张图片的情况下, LR 会自动缩放至`lr=0.08`。
+
+如果不启用该功能,则需要根据 [线性扩展规则](https://arxiv.org/abs/1706.02677) 来手动计算并修改配置文件里面 `optimizer.lr` 的值。
+
+### 使用单 GPU 训练
+
+我们提供了 `tools/train.py` 来开启在单张 GPU 上的训练任务。基本使用如下:
+
+```shell
+python tools/train.py \
+ ${CONFIG_FILE} \
+ [optional arguments]
+```
+
+在训练期间,日志文件和 checkpoint 文件将会被保存在工作目录下,它需要通过配置文件中的 `work_dir` 或者 CLI 参数中的 `--work-dir` 来指定。
+
+默认情况下,模型将在每轮训练之后在 validation 集上进行测试,测试的频率可以通过设置配置文件来指定:
+
+```python
+# 每 12 轮迭代进行一次测试评估
+evaluation = dict(interval=12)
+```
+
+这个工具接受以下参数:
+
+- `--no-validate` (**不建议**): 在训练期间关闭测试.
+- `--work-dir ${WORK_DIR}`: 覆盖工作目录.
+- `--resume-from ${CHECKPOINT_FILE}`: 从某个 checkpoint 文件继续训练.
+- `--options 'Key=value'`: 覆盖使用的配置文件中的其他设置.
+
+**注意**:
+`resume-from` 和 `load-from` 的区别:
+
+`resume-from` 既加载了模型的权重和优化器的状态,也会继承指定 checkpoint 的迭代次数,不会重新开始训练。`load-from` 则是只加载模型的权重,它的训练是从头开始的,经常被用于微调模型。
+
+### 使用 CPU 训练
+
+使用 CPU 训练的流程和使用单 GPU 训练的流程一致,我们仅需要在训练流程开始前禁用 GPU。
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+之后运行单 GPU 训练脚本即可。
+
+**注意**:
+
+我们不推荐用户使用 CPU 进行训练,这太过缓慢。我们支持这个功能是为了方便用户在没有 GPU 的机器上进行调试。
+
+### 在多 GPU 上训练
+
+我们提供了 `tools/dist_train.sh` 来开启在多 GPU 上的训练。基本使用如下:
+
+```shell
+bash ./tools/dist_train.sh \
+ ${CONFIG_FILE} \
+ ${GPU_NUM} \
+ [optional arguments]
+```
+
+可选参数和单 GPU 训练的可选参数一致。
+
+#### 同时启动多个任务
+
+如果你想在一台机器上启动多个任务的话,比如在一个有 8 块 GPU 的机器上启动 2 个需要 4 块GPU的任务,你需要给不同的训练任务指定不同的端口(默认为 29500)来避免冲突。
+
+如果你使用 `dist_train.sh` 来启动训练任务,你可以使用命令来设置端口。
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+### 使用多台机器训练
+
+如果您想使用由 ethernet 连接起来的多台机器, 您可以使用以下命令:
+
+在第一台机器上:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+在第二台机器上:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+但是,如果您不使用高速网路连接这几台机器的话,训练将会非常慢。
+
+### 使用 Slurm 来管理任务
+
+Slurm 是一个常见的计算集群调度系统。在 Slurm 管理的集群上,你可以使用 `slurm.sh` 来开启训练任务。它既支持单节点训练也支持多节点训练。
+
+基本使用如下:
+
+```shell
+[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
+```
+
+以下是在一个名称为 _dev_ 的 Slurm 分区上,使用 16 块 GPU 来训练 Mask R-CNN 的例子,并且将 `work-dir` 设置在了某些共享文件系统下。
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev mask_r50_1x configs/mask_rcnn_r50_fpn_1x_coco.py /nfs/xxxx/mask_rcnn_r50_fpn_1x
+```
+
+你可以查看 [源码](https://github.com/open-mmlab/mmdetection/blob/master/tools/slurm_train.sh) 来检查全部的参数和环境变量.
+
+在使用 Slurm 时,端口需要以下方的某个方法之一来设置。
+
+1. 通过 `--options` 来设置端口。我们非常建议用这种方法,因为它无需改变原始的配置文件。
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR} --options 'dist_params.port=29500'
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR} --options 'dist_params.port=29501'
+ ```
+
+2. 修改配置文件来设置不同的交流端口。
+
+ 在 `config1.py` 中,设置:
+
+ ```python
+ dist_params = dict(backend='nccl', port=29500)
+ ```
+
+ 在 `config2.py` 中,设置:
+
+ ```python
+ dist_params = dict(backend='nccl', port=29501)
+ ```
+
+ 然后你可以使用 `config1.py` 和 `config2.py` 来启动两个任务了。
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
+ ```
diff --git a/downstream/mmdetection/docs/zh_cn/2_new_data_model.md b/downstream/mmdetection/docs/zh_cn/2_new_data_model.md
new file mode 100644
index 0000000..f760c51
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/2_new_data_model.md
@@ -0,0 +1,267 @@
+# 2: 在自定义数据集上进行训练
+
+通过本文档,你将会知道如何使用自定义数据集对预先定义好的模型进行推理,测试以及训练。我们使用 [balloon dataset](https://github.com/matterport/Mask_RCNN/tree/master/samples/balloon) 作为例子来描述整个过程。
+
+基本步骤如下:
+
+1. 准备自定义数据集
+2. 准备配置文件
+3. 在自定义数据集上进行训练,测试和推理。
+
+## 准备自定义数据集
+
+MMDetection 一共支持三种形式应用新数据集:
+
+1. 将数据集重新组织为 COCO 格式。
+2. 将数据集重新组织为一个中间格式。
+3. 实现一个新的数据集。
+
+我们通常建议使用前面两种方法,因为它们通常来说比第三种方法要简单。
+
+在本文档中,我们展示一个例子来说明如何将数据转化为 COCO 格式。
+
+**注意**:MMDetection 现只支持对 COCO 格式的数据集进行 mask AP 的评测。
+
+所以用户如果要进行实例分割,只能将数据转成 COCO 格式。
+
+### COCO标注格式
+
+用于实例分割的 COCO 数据集格式如下所示,其中的键(key)都是必要的,参考[这里](https://cocodataset.org/#format-data)来获取更多细节。
+
+```json
+{
+ "images": [image],
+ "annotations": [annotation],
+ "categories": [category]
+}
+
+
+image = {
+ "id": int,
+ "width": int,
+ "height": int,
+ "file_name": str,
+}
+
+annotation = {
+ "id": int,
+ "image_id": int,
+ "category_id": int,
+ "segmentation": RLE or [polygon],
+ "area": float,
+ "bbox": [x,y,width,height],
+ "iscrowd": 0 or 1,
+}
+
+categories = [{
+ "id": int,
+ "name": str,
+ "supercategory": str,
+}]
+```
+
+现在假设我们使用 balloon dataset。
+
+下载了数据集之后,我们需要实现一个函数将标注格式转化为 COCO 格式。然后我们就可以使用已经实现的 `COCODataset` 类来加载数据并进行训练以及评测。
+
+如果你浏览过新数据集,你会发现格式如下:
+
+```json
+{'base64_img_data': '',
+ 'file_attributes': {},
+ 'filename': '34020010494_e5cb88e1c4_k.jpg',
+ 'fileref': '',
+ 'regions': {'0': {'region_attributes': {},
+ 'shape_attributes': {'all_points_x': [1020,
+ 1000,
+ 994,
+ 1003,
+ 1023,
+ 1050,
+ 1089,
+ 1134,
+ 1190,
+ 1265,
+ 1321,
+ 1361,
+ 1403,
+ 1428,
+ 1442,
+ 1445,
+ 1441,
+ 1427,
+ 1400,
+ 1361,
+ 1316,
+ 1269,
+ 1228,
+ 1198,
+ 1207,
+ 1210,
+ 1190,
+ 1177,
+ 1172,
+ 1174,
+ 1170,
+ 1153,
+ 1127,
+ 1104,
+ 1061,
+ 1032,
+ 1020],
+ 'all_points_y': [963,
+ 899,
+ 841,
+ 787,
+ 738,
+ 700,
+ 663,
+ 638,
+ 621,
+ 619,
+ 643,
+ 672,
+ 720,
+ 765,
+ 800,
+ 860,
+ 896,
+ 942,
+ 990,
+ 1035,
+ 1079,
+ 1112,
+ 1129,
+ 1134,
+ 1144,
+ 1153,
+ 1166,
+ 1166,
+ 1150,
+ 1136,
+ 1129,
+ 1122,
+ 1112,
+ 1084,
+ 1037,
+ 989,
+ 963],
+ 'name': 'polygon'}}},
+ 'size': 1115004}
+```
+
+标注文件时是 JSON 格式的,其中所有键(key)组成了一张图片的所有标注。
+
+其中将 balloon dataset 转化为 COCO 格式的代码如下所示。
+
+```python
+
+import os.path as osp
+import mmcv
+
+def convert_balloon_to_coco(ann_file, out_file, image_prefix):
+ data_infos = mmcv.load(ann_file)
+
+ annotations = []
+ images = []
+ obj_count = 0
+ for idx, v in enumerate(mmcv.track_iter_progress(data_infos.values())):
+ filename = v['filename']
+ img_path = osp.join(image_prefix, filename)
+ height, width = mmcv.imread(img_path).shape[:2]
+
+ images.append(dict(
+ id=idx,
+ file_name=filename,
+ height=height,
+ width=width))
+
+ bboxes = []
+ labels = []
+ masks = []
+ for _, obj in v['regions'].items():
+ assert not obj['region_attributes']
+ obj = obj['shape_attributes']
+ px = obj['all_points_x']
+ py = obj['all_points_y']
+ poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
+ poly = [p for x in poly for p in x]
+
+ x_min, y_min, x_max, y_max = (
+ min(px), min(py), max(px), max(py))
+
+
+ data_anno = dict(
+ image_id=idx,
+ id=obj_count,
+ category_id=0,
+ bbox=[x_min, y_min, x_max - x_min, y_max - y_min],
+ area=(x_max - x_min) * (y_max - y_min),
+ segmentation=[poly],
+ iscrowd=0)
+ annotations.append(data_anno)
+ obj_count += 1
+
+ coco_format_json = dict(
+ images=images,
+ annotations=annotations,
+ categories=[{'id':0, 'name': 'balloon'}])
+ mmcv.dump(coco_format_json, out_file)
+```
+
+使用如上的函数,用户可以成功将标注文件转化为 JSON 格式,之后可以使用 `CocoDataset` 对模型进行训练和评测。
+
+## 准备配置文件
+
+第二步需要准备一个配置文件来成功加载数据集。假设我们想要用 balloon dataset 来训练配备了 FPN 的 Mask R-CNN ,如下是我们的配置文件。假设配置文件命名为 `mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py`,相应保存路径为 `configs/balloon/`,配置文件内容如下所示。
+
+```python
+# 这个新的配置文件继承自一个原始配置文件,只需要突出必要的修改部分即可
+_base_ = 'mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py'
+
+# 我们需要对头中的类别数量进行修改来匹配数据集的标注
+model = dict(
+ roi_head=dict(
+ bbox_head=dict(num_classes=1),
+ mask_head=dict(num_classes=1)))
+
+# 修改数据集相关设置
+dataset_type = 'CocoDataset'
+classes = ('balloon',)
+data = dict(
+ train=dict(
+ img_prefix='balloon/train/',
+ classes=classes,
+ ann_file='balloon/train/annotation_coco.json'),
+ val=dict(
+ img_prefix='balloon/val/',
+ classes=classes,
+ ann_file='balloon/val/annotation_coco.json'),
+ test=dict(
+ img_prefix='balloon/val/',
+ classes=classes,
+ ann_file='balloon/val/annotation_coco.json'))
+
+# 我们可以使用预训练的 Mask R-CNN 来获取更好的性能
+load_from = 'checkpoints/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'
+```
+
+## 训练一个新的模型
+
+为了使用新的配置方法来对模型进行训练,你只需要运行如下命令。
+
+```shell
+python tools/train.py configs/balloon/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py
+```
+
+参考[情况 1](./1_exist_data_model.md)来获取更多详细的使用方法。
+
+## 测试以及推理
+
+为了测试训练完毕的模型,你只需要运行如下命令。
+
+```shell
+python tools/test.py configs/balloon/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py work_dirs/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py/latest.pth --eval bbox segm
+```
+
+参考[情况 1](./1_exist_data_model.md)来获取更多详细的使用方法。
diff --git a/downstream/mmdetection/docs/zh_cn/3_exist_data_new_model.md b/downstream/mmdetection/docs/zh_cn/3_exist_data_new_model.md
new file mode 100644
index 0000000..e32e373
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/3_exist_data_new_model.md
@@ -0,0 +1,283 @@
+# 3: 在标准数据集上训练自定义模型
+
+在本文中,你将知道如何在标准数据集上训练、测试和推理自定义模型。我们将在 cityscapes 数据集上以自定义 Cascade Mask R-CNN R50 模型为例演示整个过程,为了方便说明,我们将 neck 模块中的 `FPN` 替换为 `AugFPN`,并且在训练中的自动增强类中增加 `Rotate` 或 `Translate`。
+
+基本步骤如下所示:
+
+1. 准备标准数据集
+2. 准备你的自定义模型
+3. 准备配置文件
+4. 在标准数据集上对模型进行训练、测试和推理
+
+## 准备标准数据集
+
+在本文中,我们使用 cityscapes 标准数据集为例进行说明。
+
+推荐将数据集根路径采用符号链接方式链接到 `$MMDETECTION/data`。
+
+如果你的文件结构不同,你可能需要在配置文件中进行相应的路径更改。标准的文件组织格式如下所示:
+
+```none
+mmdetection
+├── mmdet
+├── tools
+├── configs
+├── data
+│ ├── coco
+│ │ ├── annotations
+│ │ ├── train2017
+│ │ ├── val2017
+│ │ ├── test2017
+│ ├── cityscapes
+│ │ ├── annotations
+│ │ ├── leftImg8bit
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── gtFine
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── VOCdevkit
+│ │ ├── VOC2007
+│ │ ├── VOC2012
+```
+
+你也可以通过如下方式设定数据集根路径
+
+```bash
+export MMDET_DATASETS=$data_root
+```
+
+我们将会使用环境便变量 `$MMDET_DATASETS` 作为数据集的根目录,因此你无需再修改相应配置文件的路径信息。
+
+你需要使用脚本 `tools/dataset_converters/cityscapes.py` 将 cityscapes 标注转化为 coco 标注格式。
+
+```shell
+pip install cityscapesscripts
+python tools/dataset_converters/cityscapes.py ./data/cityscapes --nproc 8 --out-dir ./data/cityscapes/annotations
+```
+
+目前在 `cityscapes `文件夹中的配置文件所对应模型是采用 COCO 预训练权重进行初始化的。
+
+如果你的网络不可用或者比较慢,建议你先手动下载对应的预训练权重,否则可能在训练开始时候出现错误。
+
+## 准备你的自定义模型
+
+第二步是准备你的自定义模型或者训练相关配置。假设你想在已有的 Cascade Mask R-CNN R50 检测模型基础上,新增一个新的 neck 模块 `AugFPN` 去代替默认的 `FPN`,以下是具体实现:
+
+### 1 定义新的 neck (例如 AugFPN)
+
+首先创建新文件 `mmdet/models/necks/augfpn.py`.
+
+```python
+from ..builder import NECKS
+
+@NECKS.register_module()
+class AugFPN(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False):
+ pass
+
+ def forward(self, inputs):
+ # implementation is ignored
+ pass
+```
+
+### 2 导入模块
+
+你可以采用两种方式导入模块,第一种是在 `mmdet/models/necks/__init__.py` 中添加如下内容
+
+```python
+from .augfpn import AugFPN
+```
+
+第二种是增加如下代码到对应配置中,这种方式的好处是不需要改动代码
+
+```python
+custom_imports = dict(
+ imports=['mmdet.models.necks.augfpn.py'],
+ allow_failed_imports=False)
+```
+
+### 3 修改配置
+
+```python
+neck=dict(
+ type='AugFPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5)
+```
+
+关于自定义模型其余相关细节例如实现新的骨架网络,头部网络、损失函数,以及运行时训练配置例如定义新的优化器、使用梯度裁剪、定制训练调度策略和钩子等,请参考文档 [自定义模型](tutorials/customize_models.md) 和 [自定义运行时训练配置](tutorials/customize_runtime.md)。
+
+## 准备配置文件
+
+第三步是准备训练配置所需要的配置文件。假设你打算基于 cityscapes 数据集,在 Cascade Mask R-CNN R50 中新增 `AugFPN` 模块,同时增加 `Rotate` 或者 `Translate` 数据增强策略,假设你的配置文件位于 `configs/cityscapes/` 目录下,并且取名为 `cascade_mask_rcnn_r50_augfpn_autoaug_10e_cityscapes.py`,则配置信息如下:
+
+```python
+# 继承 base 配置,然后进行针对性修改
+_base_ = [
+ '../_base_/models/cascade_mask_rcnn_r50_fpn.py',
+ '../_base_/datasets/cityscapes_instance.py', '../_base_/default_runtime.py'
+]
+
+model = dict(
+ # 设置为 None,表示不加载 ImageNet 预训练权重,
+ # 后续可以设置 `load_from` 参数用来加载 COCO 预训练权重
+ backbone=dict(init_cfg=None),
+ pretrained=None,
+ # 使用新增的 `AugFPN` 模块代替默认的 `FPN`
+ neck=dict(
+ type='AugFPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ # 我们也需要将 num_classes 从 80 修改为 8 来匹配 cityscapes 数据集标注
+ # 这个修改包括 `bbox_head` 和 `mask_head`.
+ roi_head=dict(
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ # 将 COCO 类别修改为 cityscapes 类别
+ num_classes=8,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ # 将 COCO 类别修改为 cityscapes 类别
+ num_classes=8,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ # 将 COCO 类别修改为 cityscapes 类别
+ num_classes=8,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ],
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ # 将 COCO 类别修改为 cityscapes 类别
+ num_classes=8,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))))
+
+# 覆写 `train_pipeline`,然后新增 `AutoAugment` 训练配置
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='AutoAugment',
+ policies=[
+ [dict(
+ type='Rotate',
+ level=5,
+ img_fill_val=(124, 116, 104),
+ prob=0.5,
+ scale=1)
+ ],
+ [dict(type='Rotate', level=7, img_fill_val=(124, 116, 104)),
+ dict(
+ type='Translate',
+ level=5,
+ prob=0.5,
+ img_fill_val=(124, 116, 104))
+ ],
+ ]),
+ dict(
+ type='Resize', img_scale=[(2048, 800), (2048, 1024)], keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
+]
+
+# 设置每张显卡的批处理大小,同时设置新的训练 pipeline
+data = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=3,
+ # 用新的训练 pipeline 配置覆写 pipeline
+ train=dict(dataset=dict(pipeline=train_pipeline)))
+
+# 设置优化器
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# 设置定制的学习率策略
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8])
+runner = dict(type='EpochBasedRunner', max_epochs=10)
+
+# 我们采用 COCO 预训练过的 Cascade Mask R-CNN R50 模型权重作为初始化权重,可以得到更加稳定的性能
+load_from = 'http://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_r50_fpn_1x_coco/cascade_mask_rcnn_r50_fpn_1x_coco_20200203-9d4dcb24.pth'
+```
+
+## 训练新模型
+
+为了能够使用新增配置来训练模型,你可以运行如下命令:
+
+```shell
+python tools/train.py configs/cityscapes/cascade_mask_rcnn_r50_augfpn_autoaug_10e_cityscapes.py
+```
+
+如果想了解更多用法,可以参考 [例子1](1_exist_data_model.md)。
+
+## 测试和推理
+
+为了能够测试训练好的模型,你可以运行如下命令:
+
+```shell
+python tools/test.py configs/cityscapes/cascade_mask_rcnn_r50_augfpn_autoaug_10e_cityscapes.py work_dirs/cascade_mask_rcnn_r50_augfpn_autoaug_10e_cityscapes.py/latest.pth --eval bbox segm
+```
+
+如果想了解更多用法,可以参考 [例子1](1_exist_data_model.md)。
diff --git a/downstream/mmdetection/docs/zh_cn/Makefile b/downstream/mmdetection/docs/zh_cn/Makefile
new file mode 100644
index 0000000..d4bb2cb
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/downstream/mmdetection/docs/zh_cn/_static/css/readthedocs.css b/downstream/mmdetection/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000..57ed0ad
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../image/mmdet-logo.png");
+ background-size: 156px 40px;
+ height: 40px;
+ width: 156px;
+}
diff --git a/downstream/mmdetection/docs/zh_cn/_static/image/mmdet-logo.png b/downstream/mmdetection/docs/zh_cn/_static/image/mmdet-logo.png
new file mode 100644
index 0000000..58e2b5e
Binary files /dev/null and b/downstream/mmdetection/docs/zh_cn/_static/image/mmdet-logo.png differ
diff --git a/downstream/mmdetection/docs/zh_cn/api.rst b/downstream/mmdetection/docs/zh_cn/api.rst
new file mode 100644
index 0000000..c75a467
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/api.rst
@@ -0,0 +1,108 @@
+mmdet.apis
+--------------
+.. automodule:: mmdet.apis
+ :members:
+
+mmdet.core
+--------------
+
+anchor
+^^^^^^^^^^
+.. automodule:: mmdet.core.anchor
+ :members:
+
+bbox
+^^^^^^^^^^
+.. automodule:: mmdet.core.bbox
+ :members:
+
+export
+^^^^^^^^^^
+.. automodule:: mmdet.core.export
+ :members:
+
+mask
+^^^^^^^^^^
+.. automodule:: mmdet.core.mask
+ :members:
+
+evaluation
+^^^^^^^^^^
+.. automodule:: mmdet.core.evaluation
+ :members:
+
+post_processing
+^^^^^^^^^^^^^^^
+.. automodule:: mmdet.core.post_processing
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmdet.core.utils
+ :members:
+
+mmdet.datasets
+--------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmdet.datasets
+ :members:
+
+pipelines
+^^^^^^^^^^
+.. automodule:: mmdet.datasets.pipelines
+ :members:
+
+samplers
+^^^^^^^^^^
+.. automodule:: mmdet.datasets.samplers
+ :members:
+
+api_wrappers
+^^^^^^^^^^
+.. automodule:: mmdet.datasets.api_wrappers
+ :members:
+
+mmdet.models
+--------------
+
+detectors
+^^^^^^^^^^
+.. automodule:: mmdet.models.detectors
+ :members:
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmdet.models.backbones
+ :members:
+
+necks
+^^^^^^^^^^^^
+.. automodule:: mmdet.models.necks
+ :members:
+
+dense_heads
+^^^^^^^^^^^^
+.. automodule:: mmdet.models.dense_heads
+ :members:
+
+roi_heads
+^^^^^^^^^^
+.. automodule:: mmdet.models.roi_heads
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmdet.models.losses
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmdet.models.utils
+ :members:
+
+mmdet.utils
+--------------
+.. automodule::mmdet.utils
+ :members:
diff --git a/downstream/mmdetection/docs/zh_cn/article.md b/downstream/mmdetection/docs/zh_cn/article.md
new file mode 100644
index 0000000..9cd6fb6
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/article.md
@@ -0,0 +1,53 @@
+## 中文解读文案汇总
+
+### 1 官方解读文案
+
+#### 1.1 框架解读
+
+- **[轻松掌握 MMDetection 整体构建流程(一)](https://zhuanlan.zhihu.com/p/337375549)**
+- **[轻松掌握 MMDetection 整体构建流程(二)](https://zhuanlan.zhihu.com/p/341954021)**
+- **[轻松掌握 MMDetection 中 Head 流程](https://zhuanlan.zhihu.com/p/343433169)**
+
+#### 1.2 算法解读
+
+- **[轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解](https://zhuanlan.zhihu.com/p/346198300)**
+- **[轻松掌握 MMDetection 中常用算法(二):Faster R-CNN|Mask R-CNN](https://zhuanlan.zhihu.com/p/349807581)**
+- [轻松掌握 MMDetection 中常用算法(三):FCOS](https://zhuanlan.zhihu.com/p/358056615)
+- [轻松掌握 MMDetection 中常用算法(四):ATSS](https://zhuanlan.zhihu.com/p/358125611)
+- [轻松掌握 MMDetection 中常用算法(五):Cascade R-CNN](https://zhuanlan.zhihu.com/p/360952172)
+- [轻松掌握 MMDetection 中常用算法(六):YOLOF](https://zhuanlan.zhihu.com/p/370758213)
+- [轻松掌握 MMDetection 中常用算法(七):CenterNet](https://zhuanlan.zhihu.com/p/374891478)
+- [轻松掌握 MMDetection 中常用算法(八):YOLACT](https://zhuanlan.zhihu.com/p/376347955)
+- [轻松掌握 MMDetection 中常用算法(九):AutoAssign](https://zhuanlan.zhihu.com/p/378581552)
+- [YOLOX 在 MMDetection 中复现全流程解析](https://zhuanlan.zhihu.com/p/398545304)
+- [喂喂喂!你可以减重了!小模型 - MMDetection 新增SSDLite 、 MobileNetV2YOLOV3 两大经典算法](https://zhuanlan.zhihu.com/p/402781143)
+
+#### 1.3 工具解读
+
+- [OpenMMLab 中混合精度训练 AMP 的正确打开方式](https://zhuanlan.zhihu.com/p/375224982)
+- [小白都能看懂!手把手教你使用混淆矩阵分析目标检测](https://zhuanlan.zhihu.com/p/443499860)
+- [MMDetection 图像缩放 Resize 详细说明 OpenMMLab](https://zhuanlan.zhihu.com/p/381117525)
+- [拿什么拯救我的 4G 显卡](https://zhuanlan.zhihu.com/p/430123077)
+- [MMDet居然能用MMCls的Backbone?论配置文件的打开方式](https://zhuanlan.zhihu.com/p/436865195)
+
+#### 1.4 知乎问答
+
+- [COCO数据集上1x模式下为什么不采用多尺度训练?](https://www.zhihu.com/question/462170786/answer/1915119662)
+- [MMDetection中SOTA论文源码中将训练过程中BN层的eval打开?](https://www.zhihu.com/question/471189603/answer/2195540892)
+- [基于PyTorch的MMDetection中训练的随机性来自何处?](https://www.zhihu.com/question/453511684/answer/1839683634)
+- [单阶段、双阶段、anchor-based、anchor-free 这四者之间有什么联系吗?](https://www.zhihu.com/question/428972054/answer/1619925296)
+- [目标检测的深度学习方法,有推荐的书籍或资料吗?](https://www.zhihu.com/question/391577080/answer/1612593817)
+- [大佬们,刚入学研究生,想入门目标检测,有什么学习路线可以入门的?](https://www.zhihu.com/question/343768934/answer/1612580715)
+- [目标检测领域还有什么可以做的?](https://www.zhihu.com/question/280703314/answer/1627885518)
+- [如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗?](https://www.zhihu.com/question/437495132/answer/1686380553)
+- [MMDetection如何学习源码?](https://www.zhihu.com/question/451585041/answer/1832498963)
+- [如何具体上手实现目标检测呢?](https://www.zhihu.com/question/341401981/answer/1848561187)
+
+#### 1.5 其他
+
+- **[不得不知的 MMDetection 学习路线(个人经验版)](https://zhuanlan.zhihu.com/p/369826931)**
+- [OpenMMLab 社区专访之 YOLOX 复现篇](https://zhuanlan.zhihu.com/p/405913343)
+
+### 2 社区解读文案
+
+- [手把手带你实现经典检测网络 Mask R-CNN 的推理](https://zhuanlan.zhihu.com/p/414082071)
diff --git a/downstream/mmdetection/docs/zh_cn/compatibility.md b/downstream/mmdetection/docs/zh_cn/compatibility.md
new file mode 100644
index 0000000..e9ebdd9
--- /dev/null
+++ b/downstream/mmdetection/docs/zh_cn/compatibility.md
@@ -0,0 +1,177 @@
+# MMDetection v2.x 兼容性说明
+
+## MMDetection 2.25.0
+
+为了加入 Mask2Former 实例分割模型,对 Mask2Former 的配置文件进行了重命名 [PR #7571](https://github.com/open-mmlab/mmdetection/pull/7571):
+
+ +
+ +
+ +
+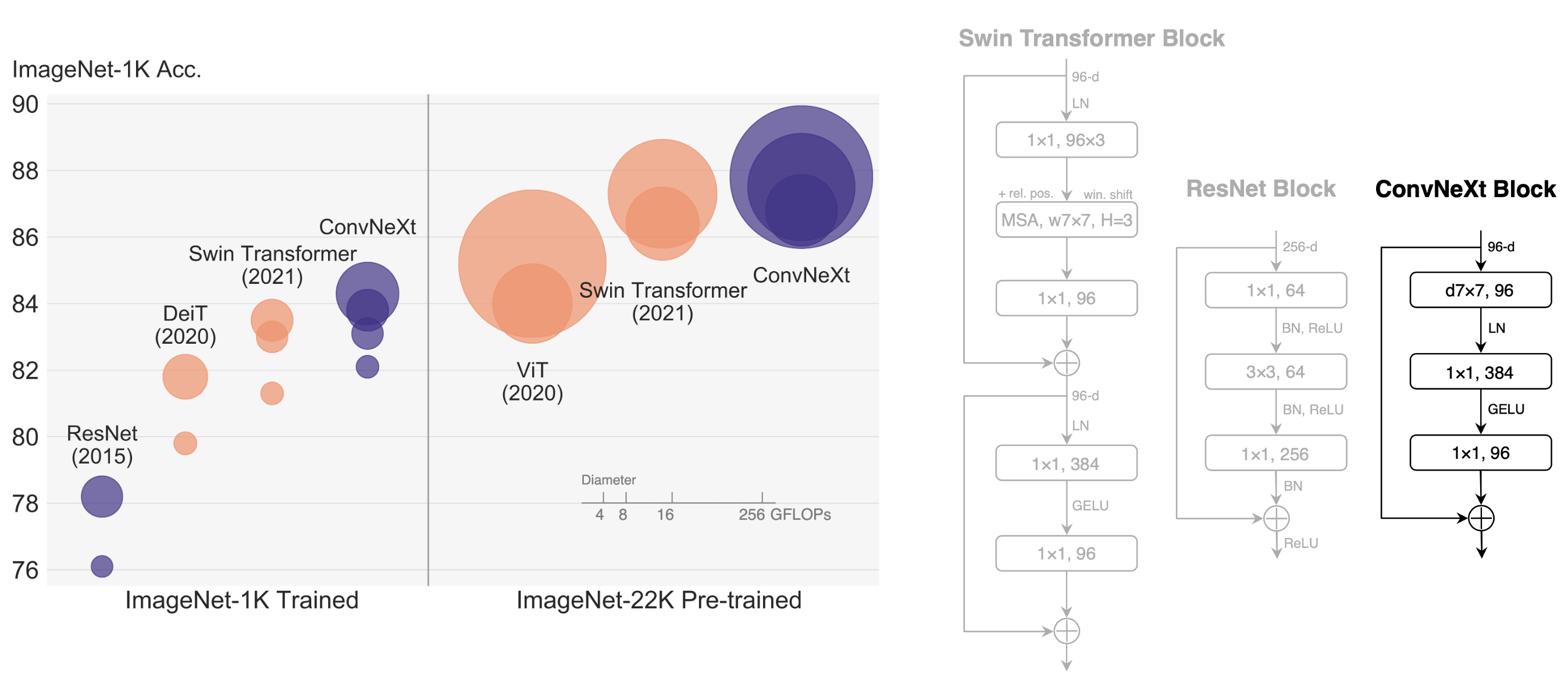 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+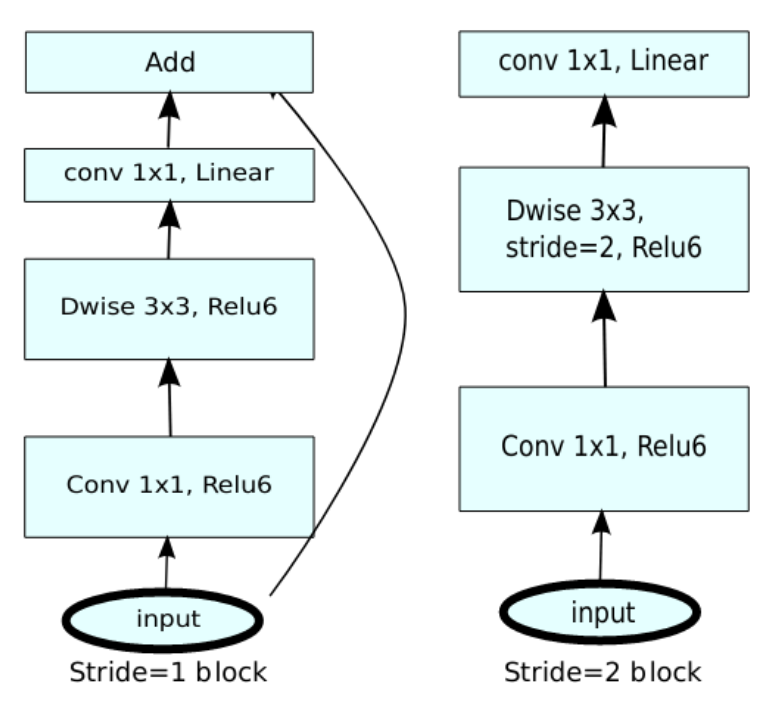 +
+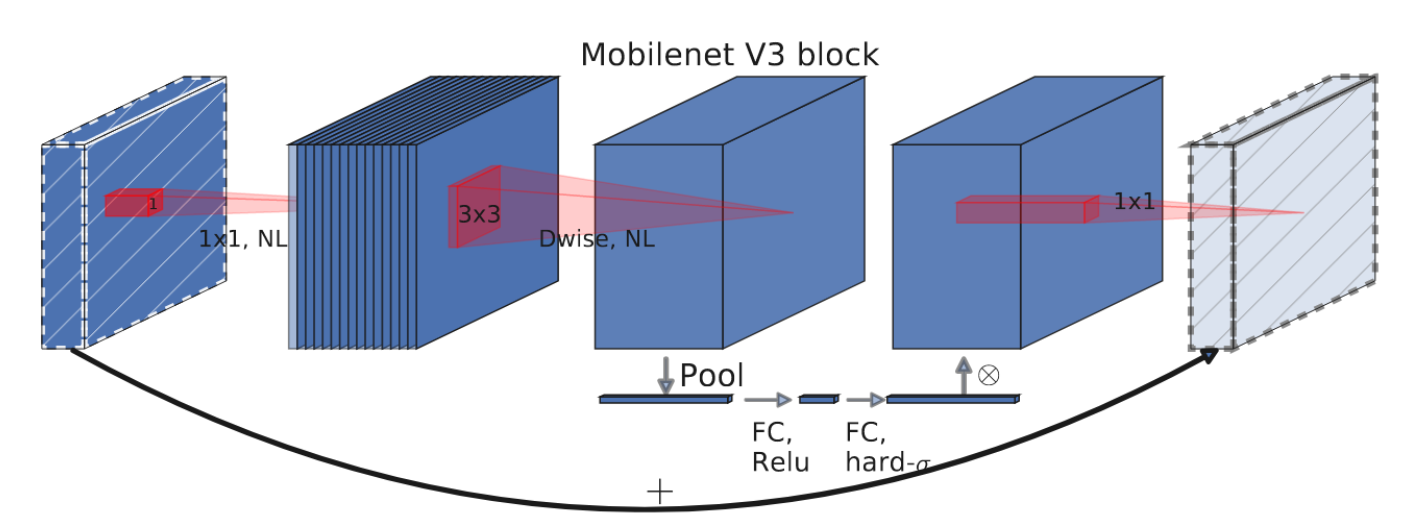 +
+ +
+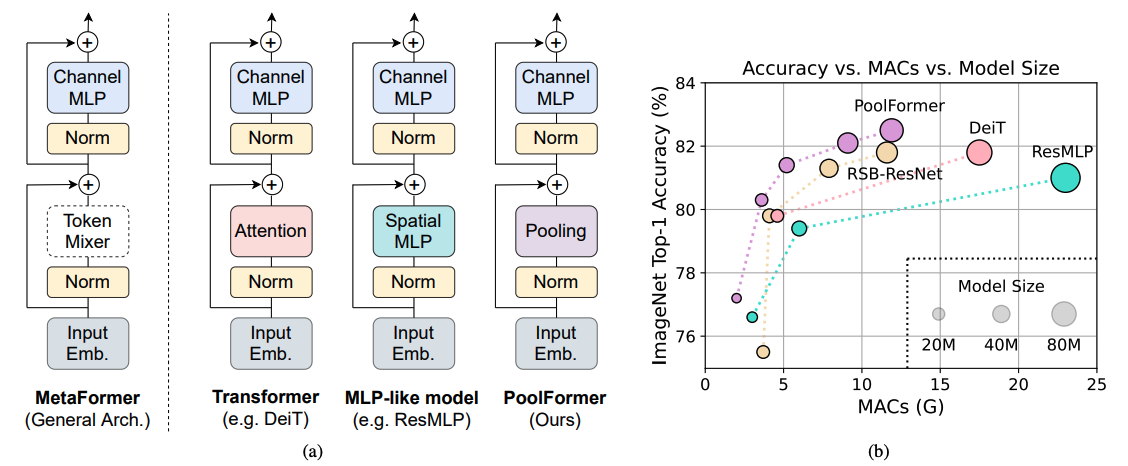 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+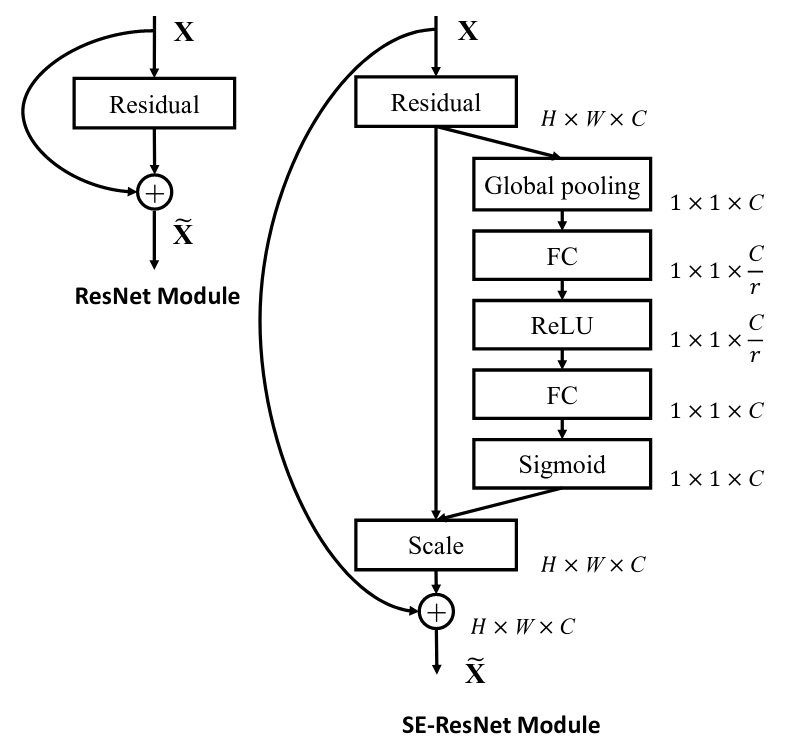 +
+ +
+ +
+ +
+ +
+ +
+ +
+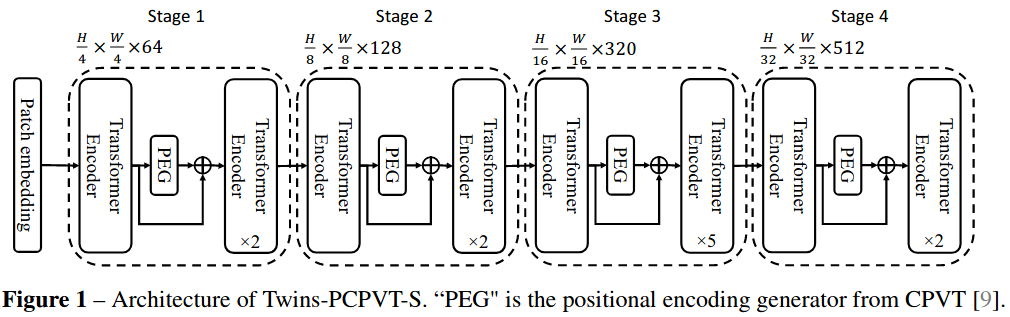 +
+ +
+ +
+ +
+ +
+



























 +
+
+
+ +
+ +
+ +
+ +
+ +
+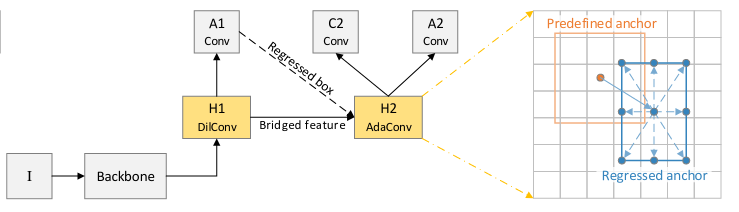 +
+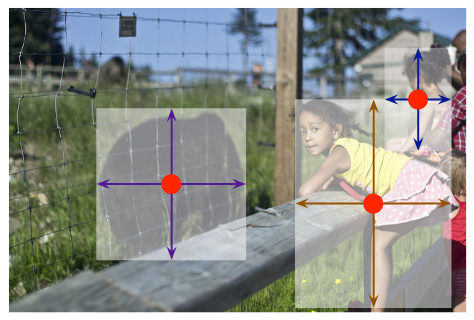 +
+ +
+ +
+ +
+ +
+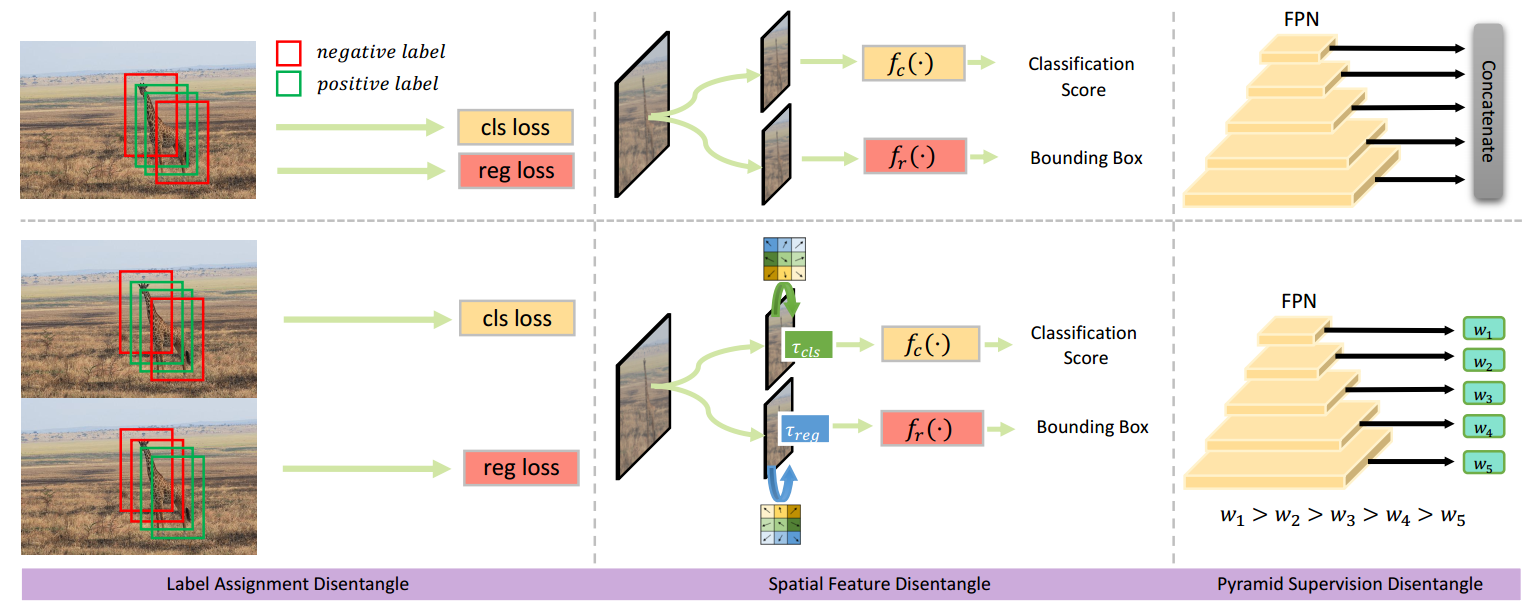 +
+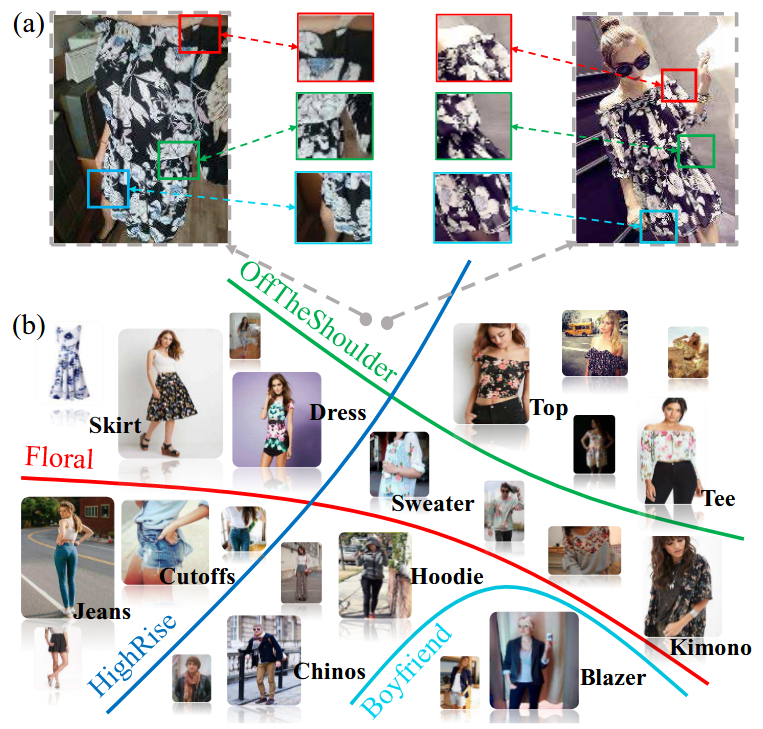 +
+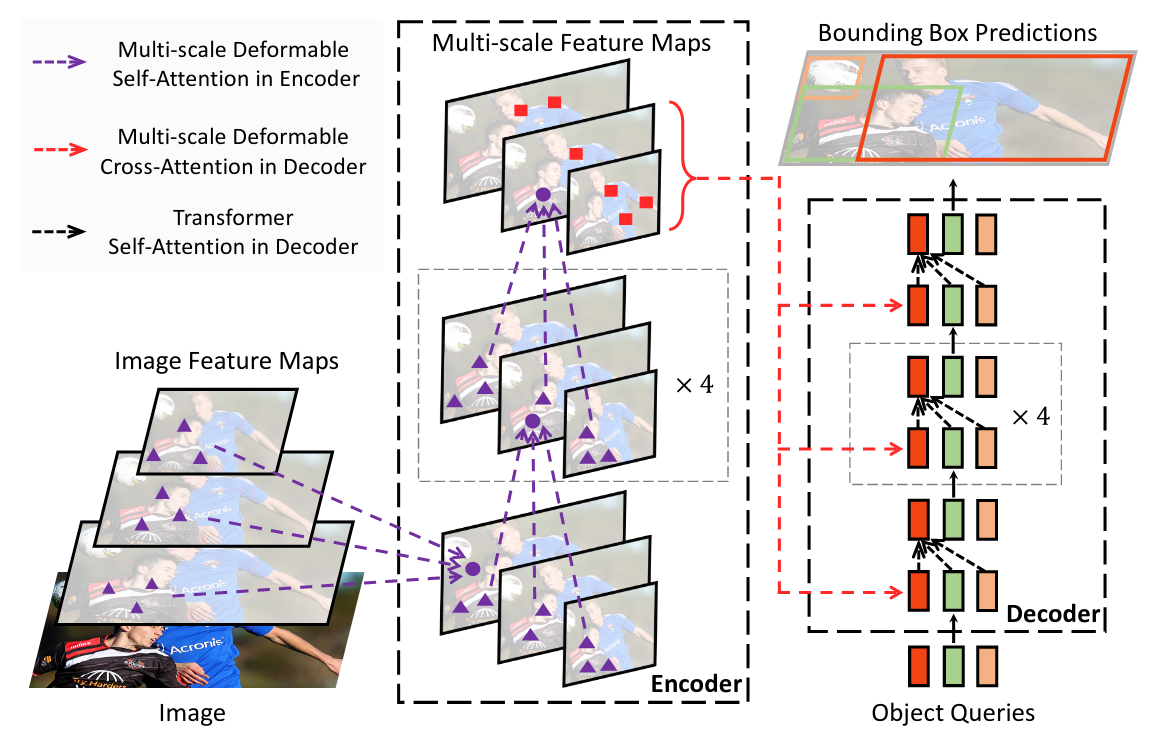 +
+ +
+ +
+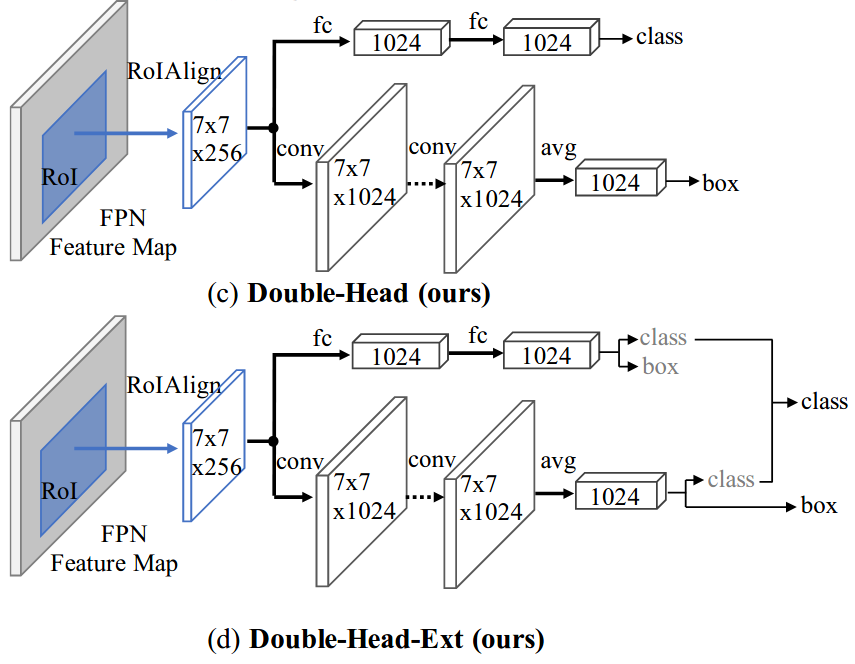 +
+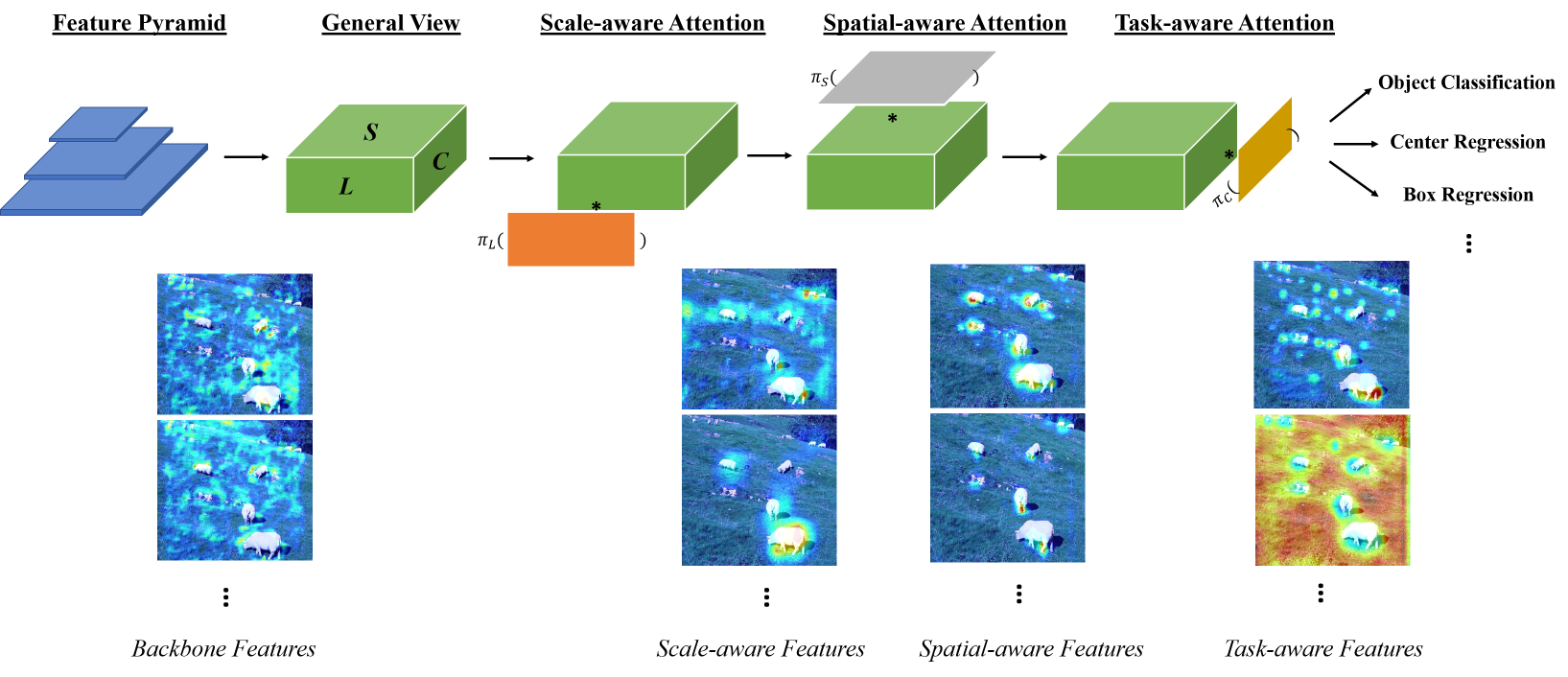 +
+ +
+ +
+ +
+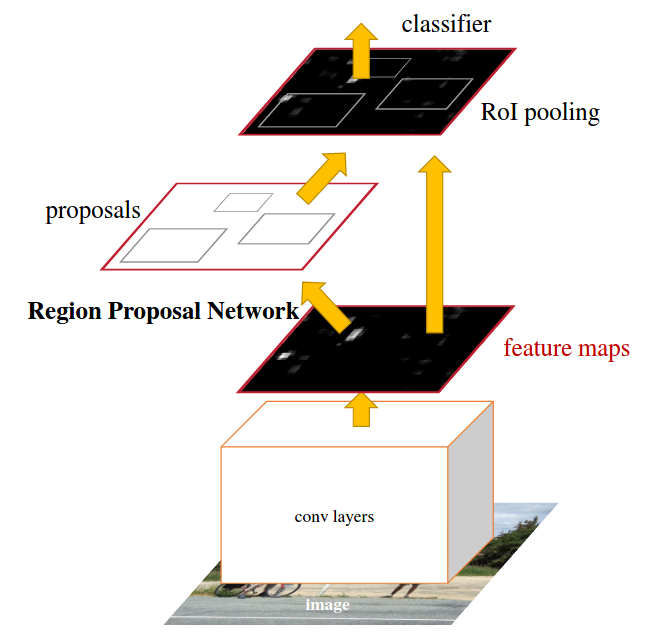 +
+ +
+ +
+ +
+ +
+ +
+ +
+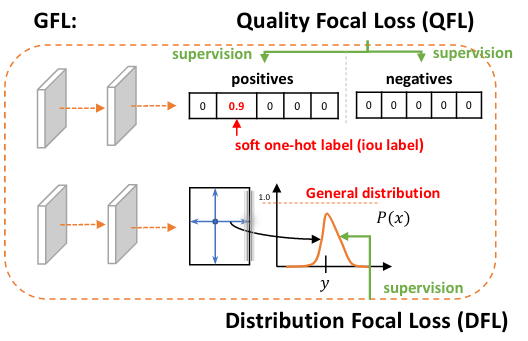 +
+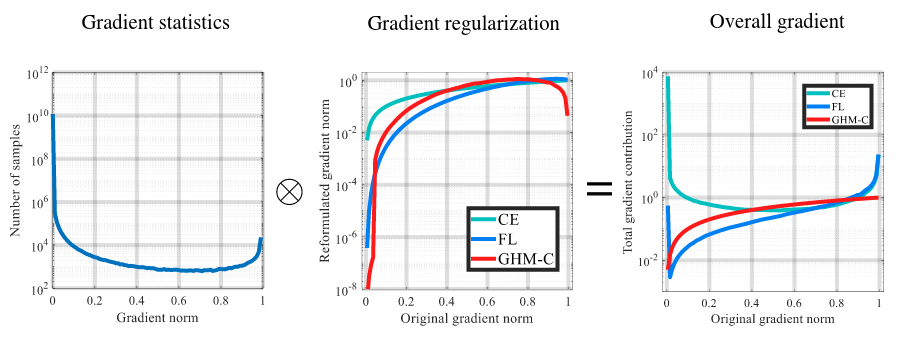 +
+ +
+ +
+ +
+ +
+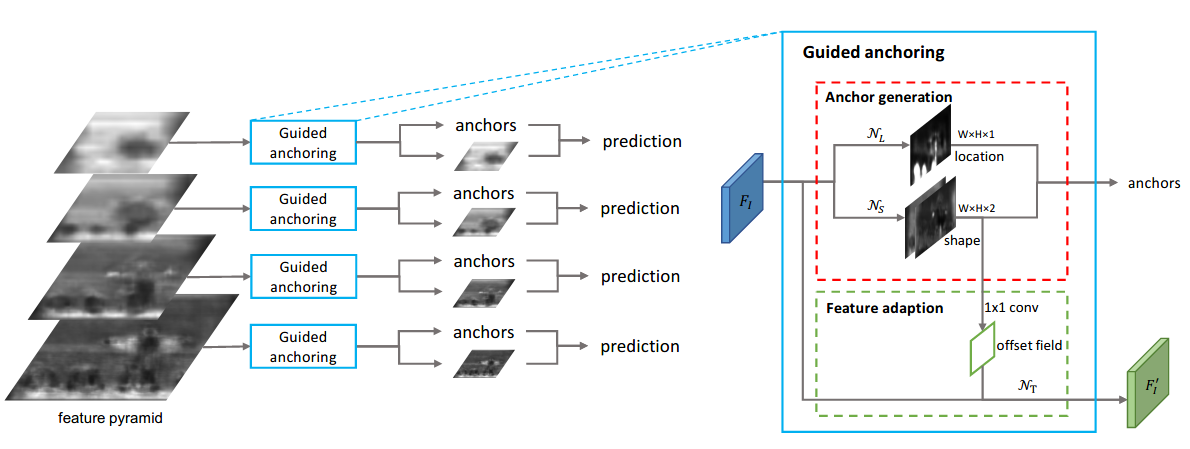 +
+ +
+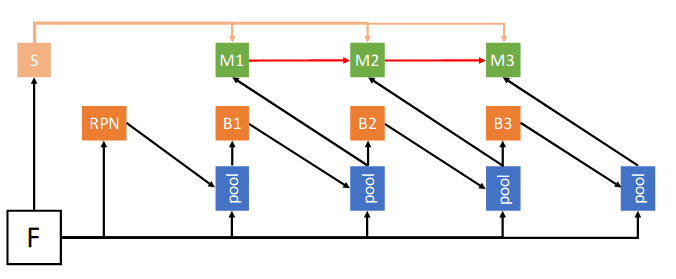 +
+ +
+ +
+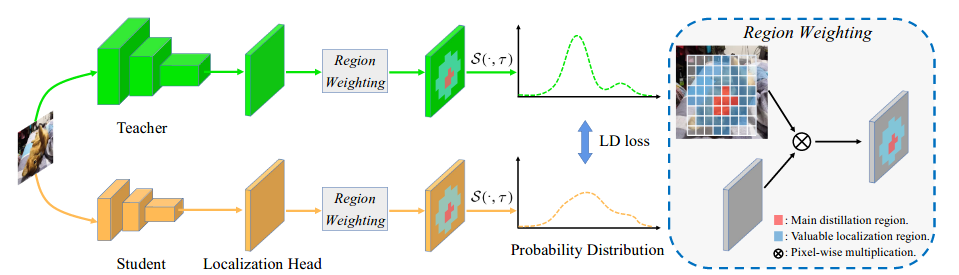 +
+ +
+ +
+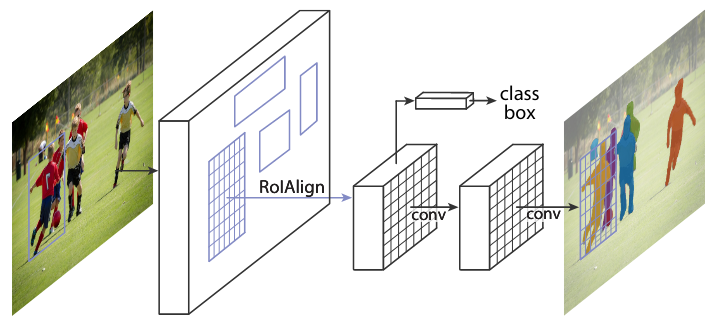 +
+ +
+ +
+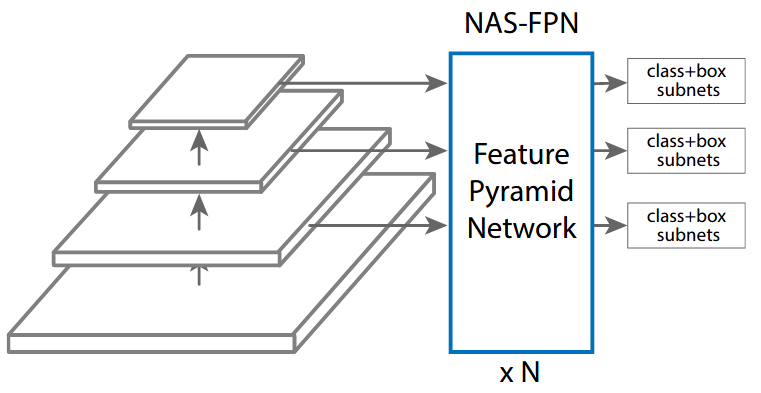 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+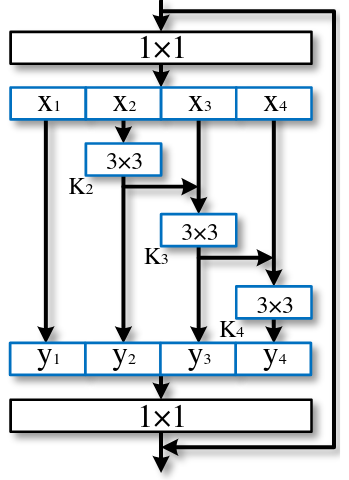 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+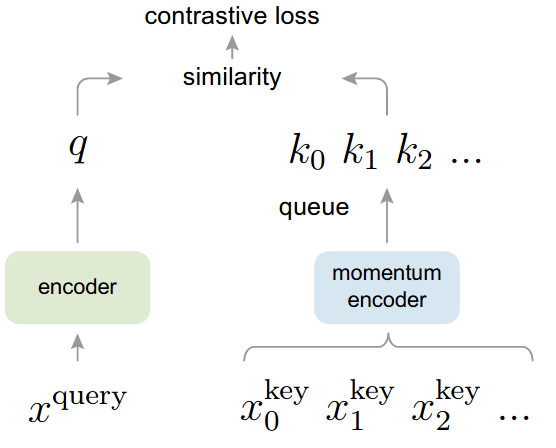 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+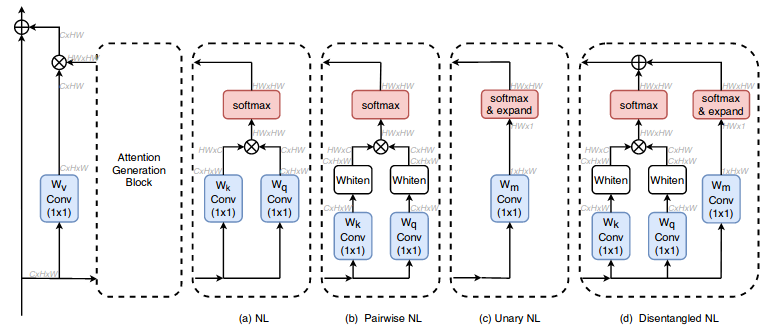 +
+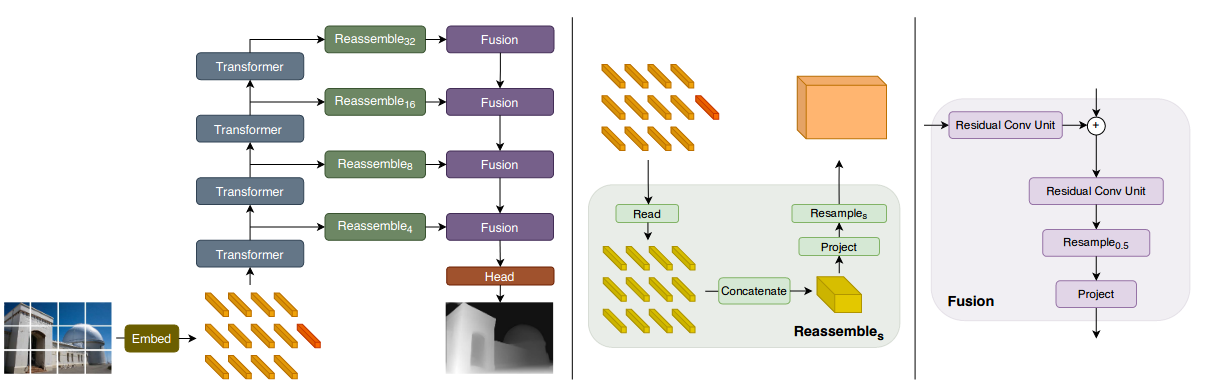 +
+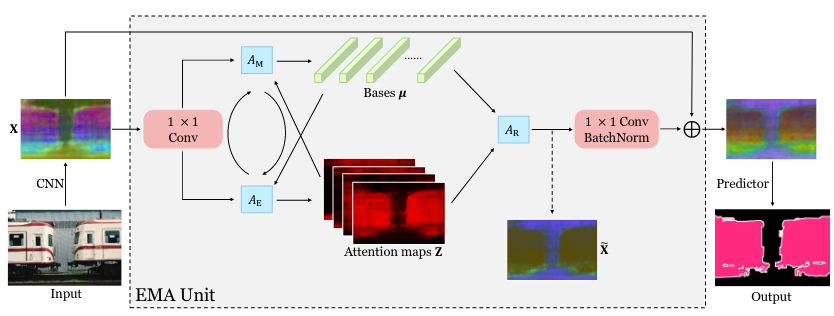 +
+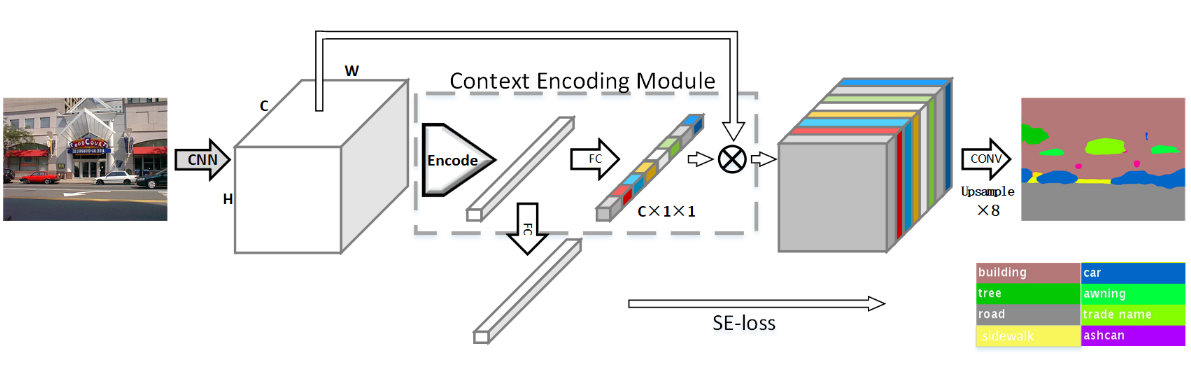 +
+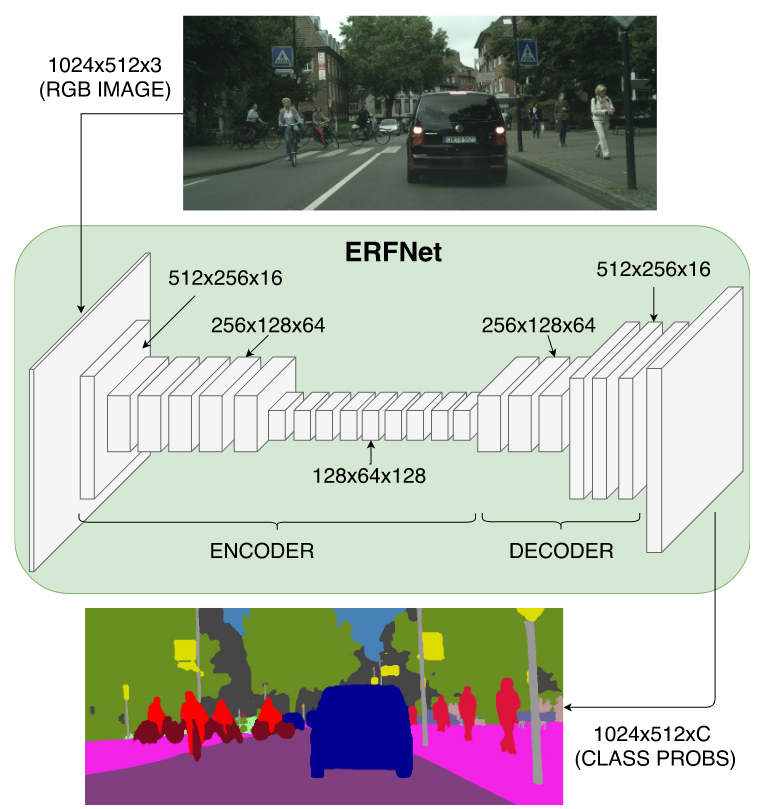 +
+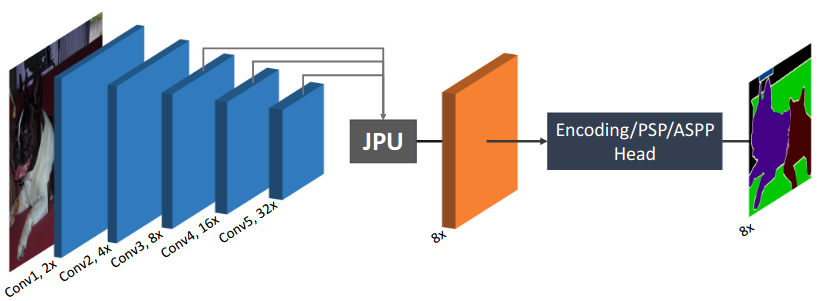 +
+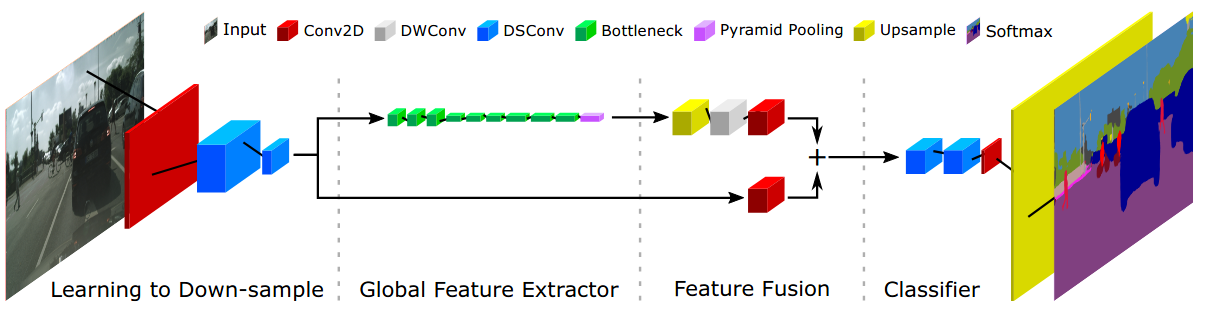 +
+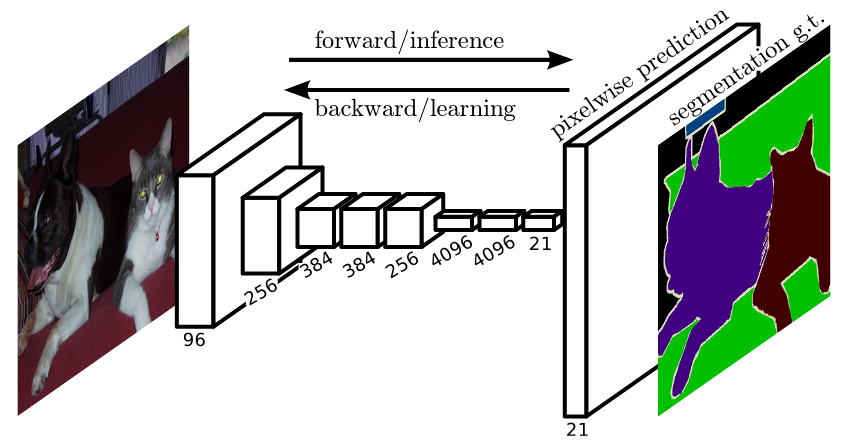 +
+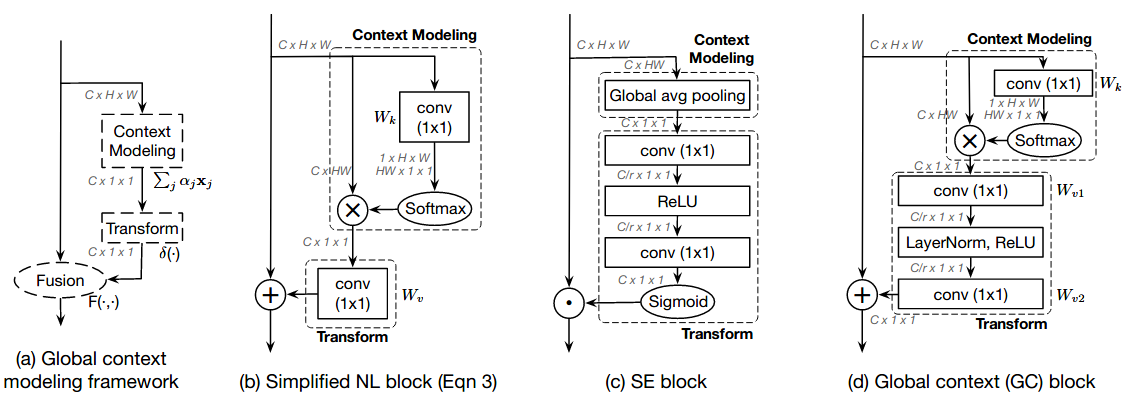 +
+ +
+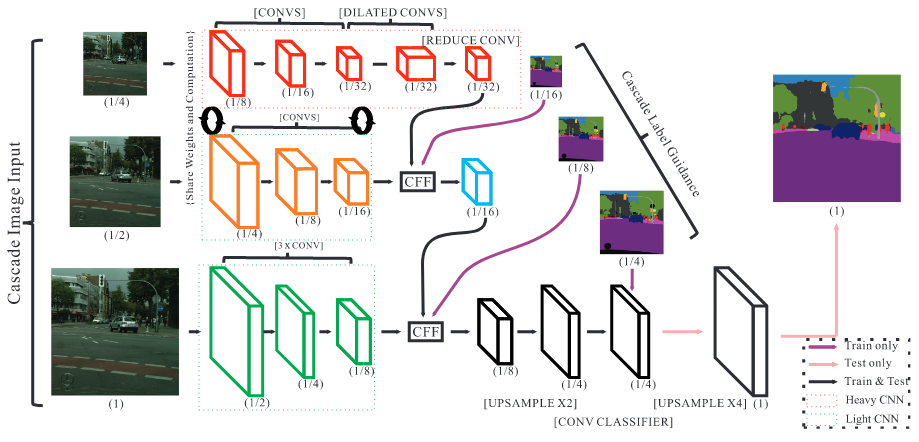 +
+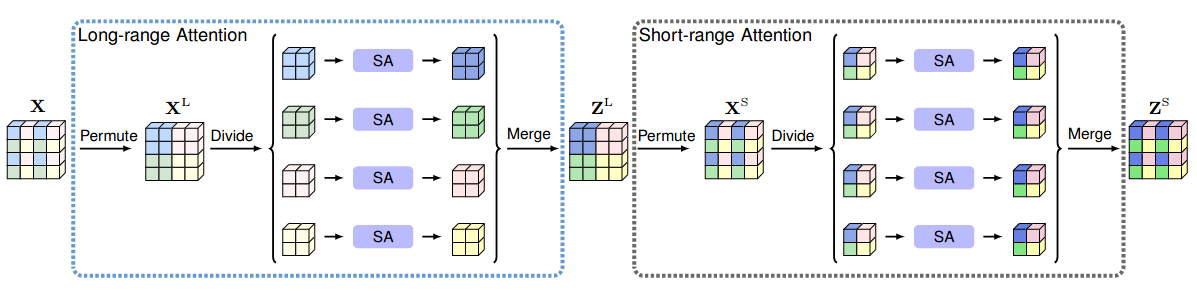 +
+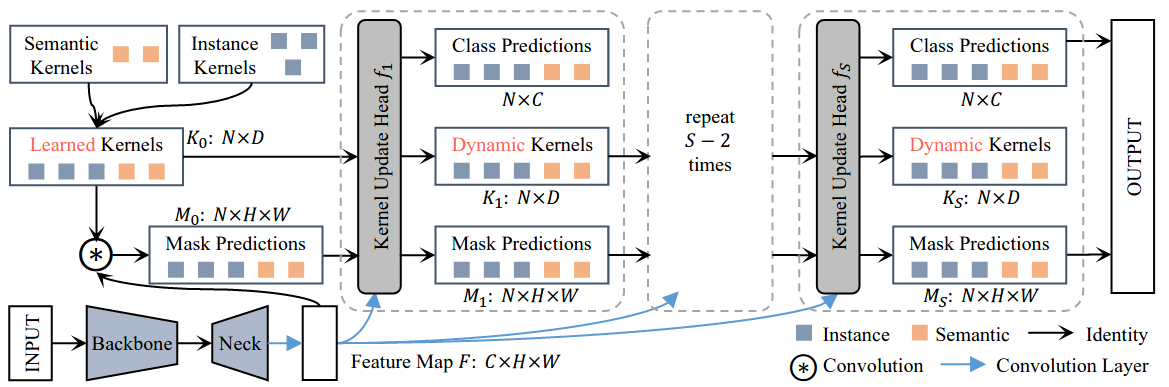 +
+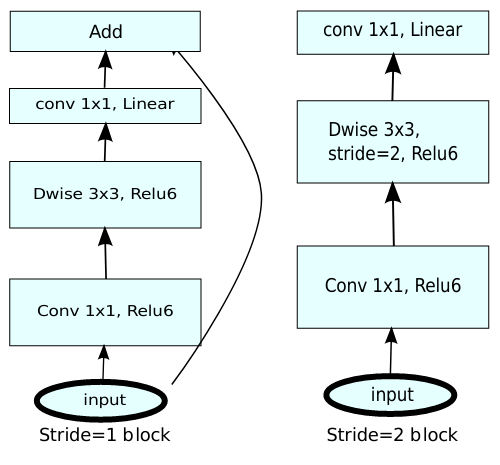 +
+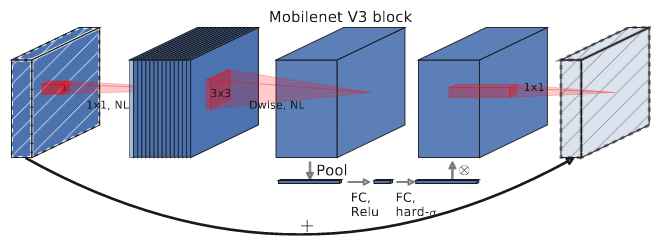 +
+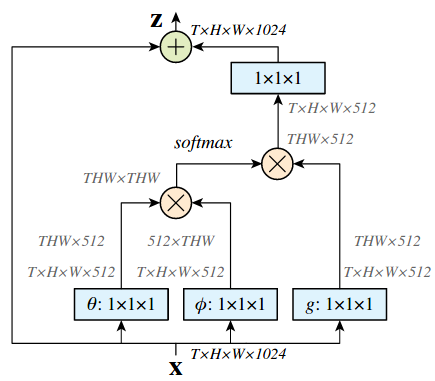 +
+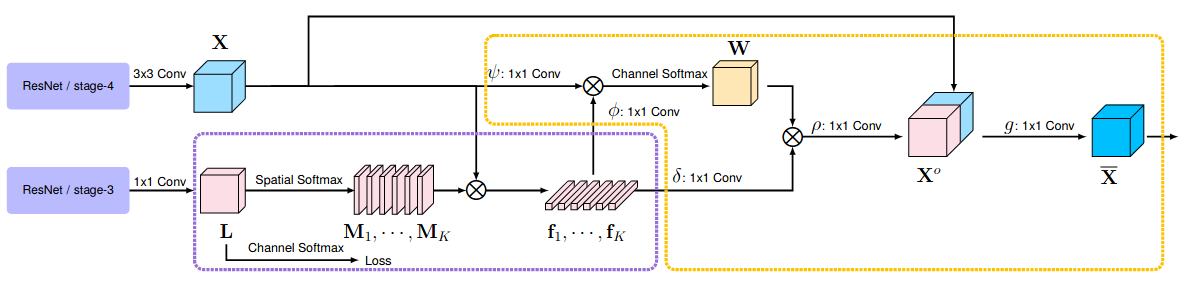 +
+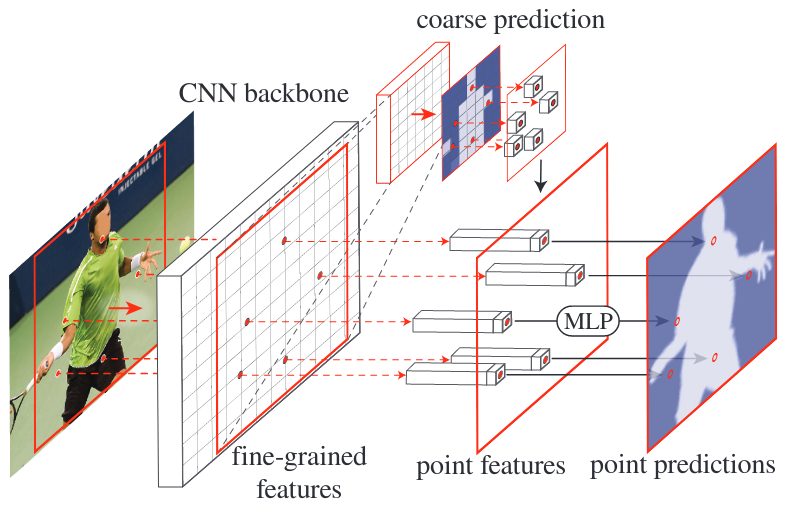 +
+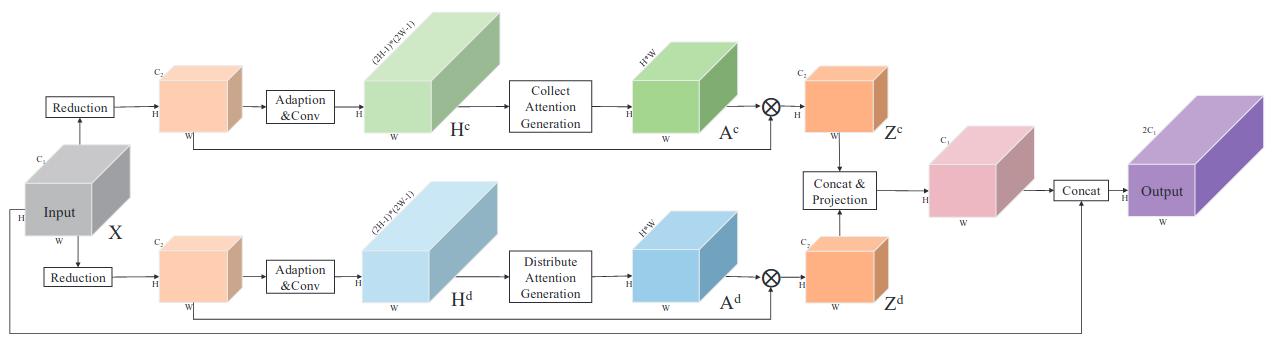 +
+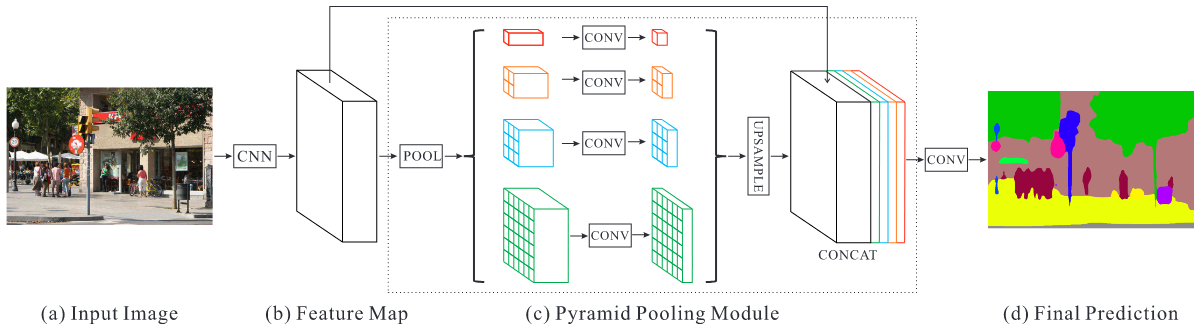 +
+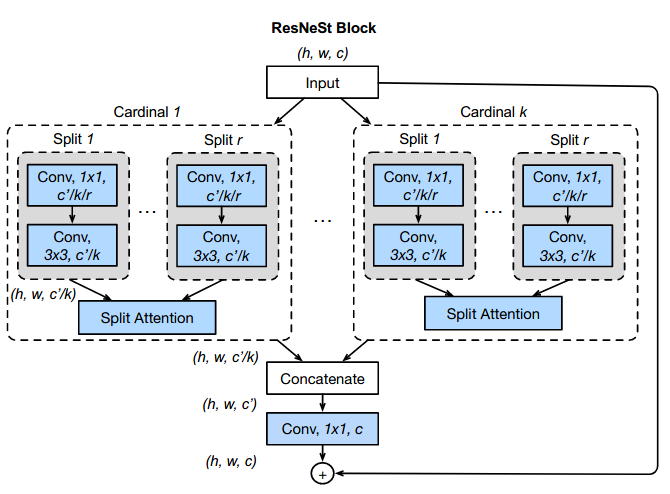 +
+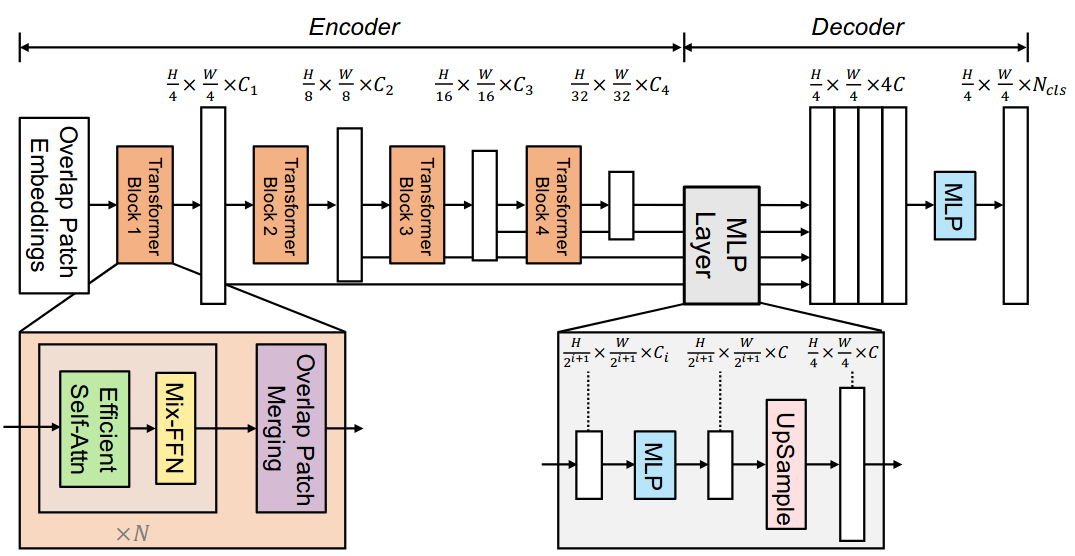 +
+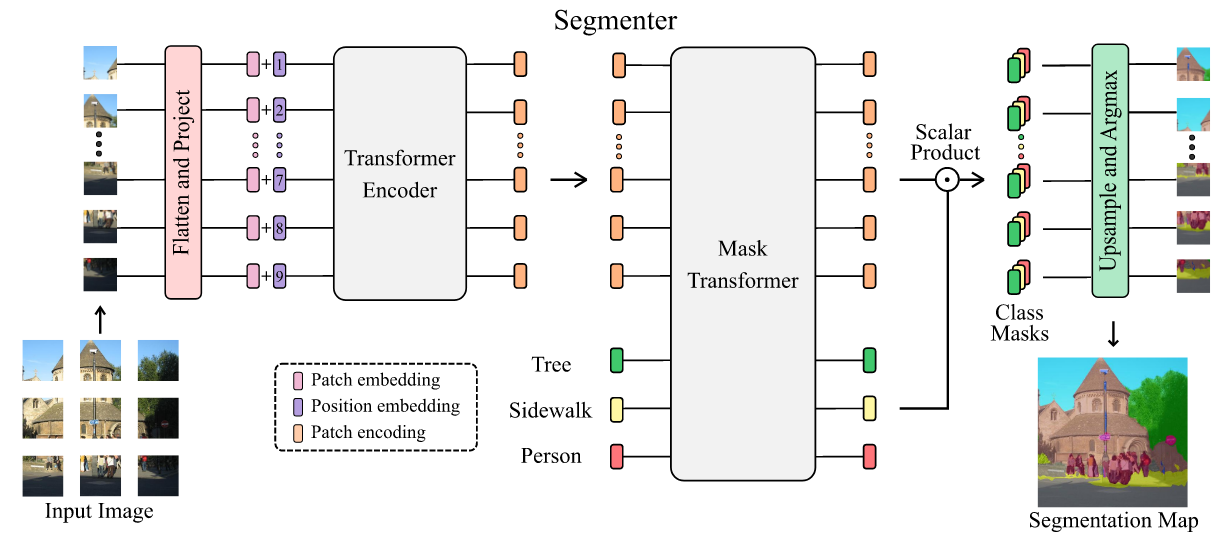 +
+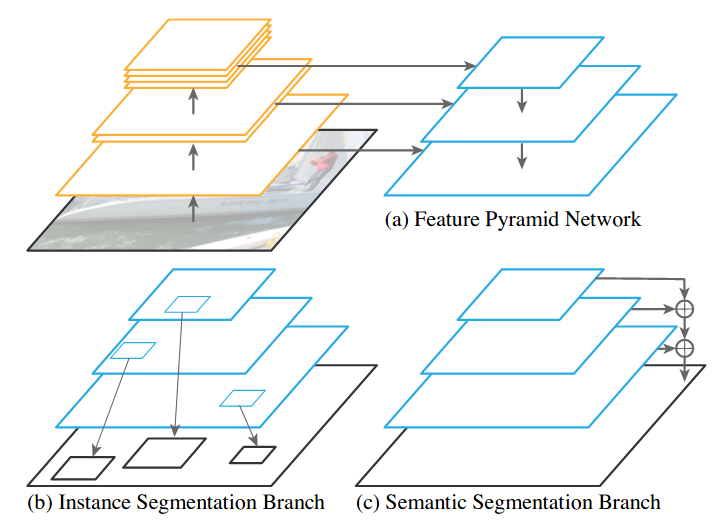 +
+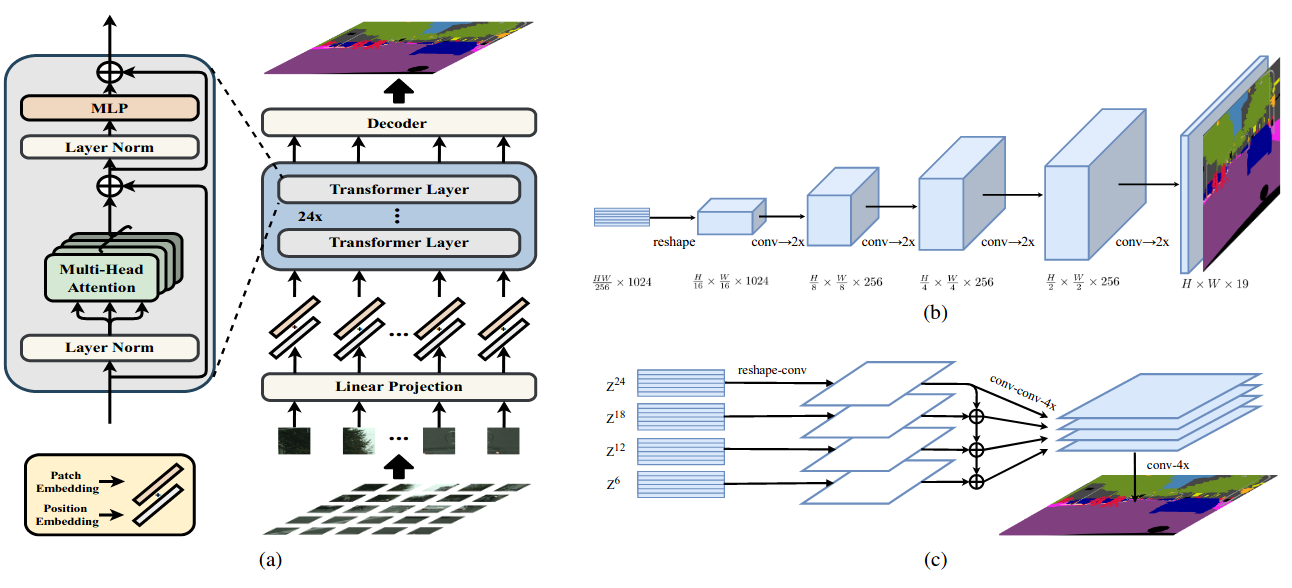 +
+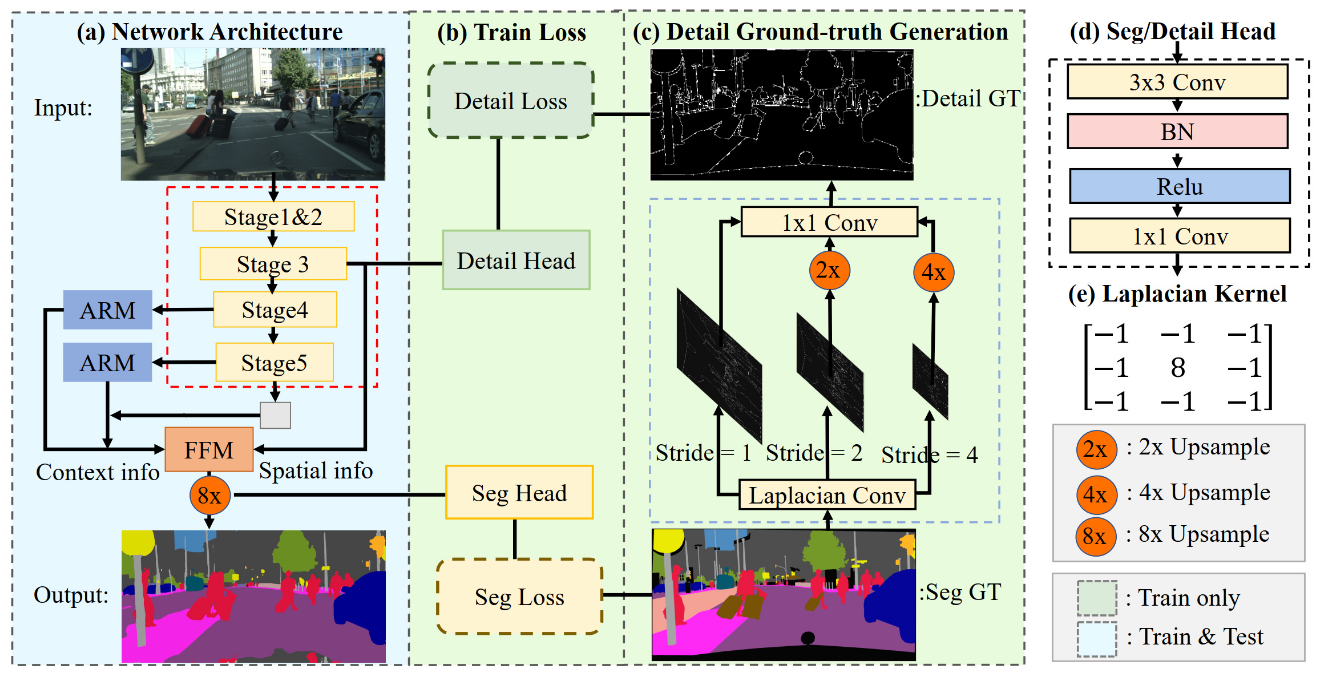 +
+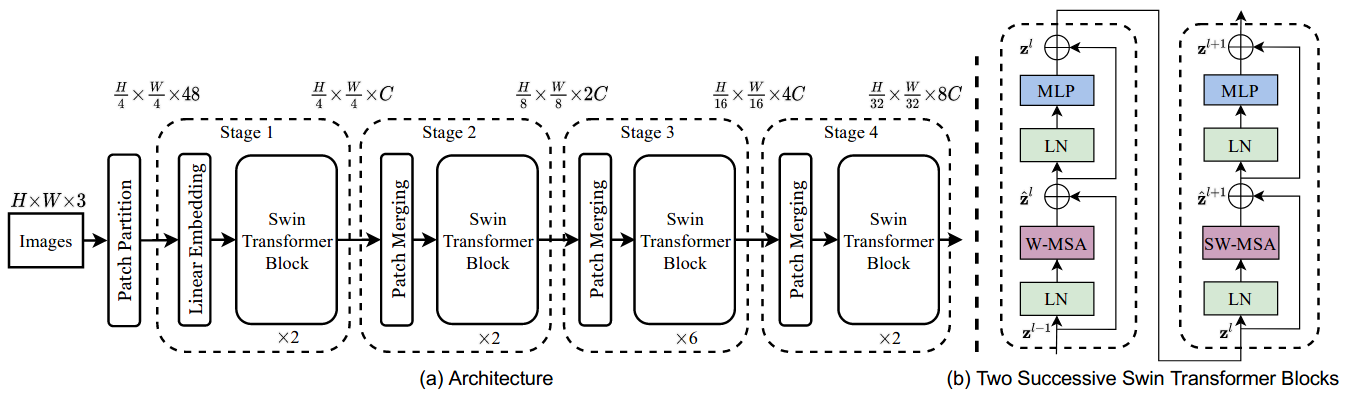 +
+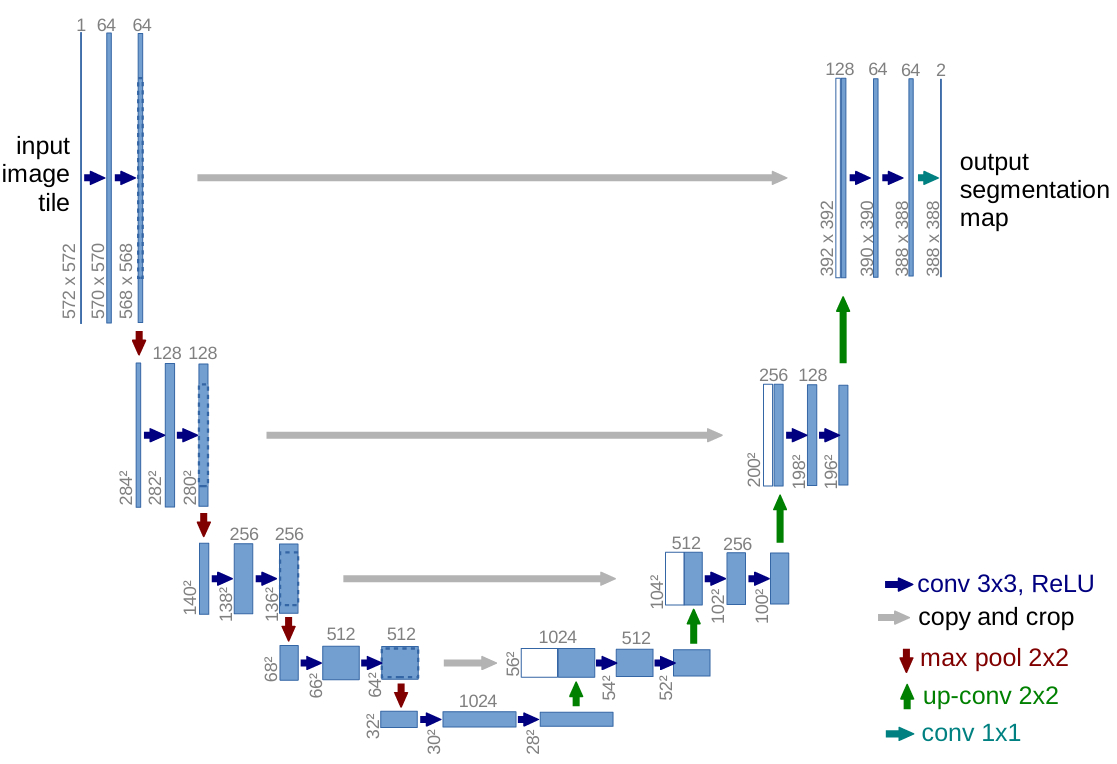 +
+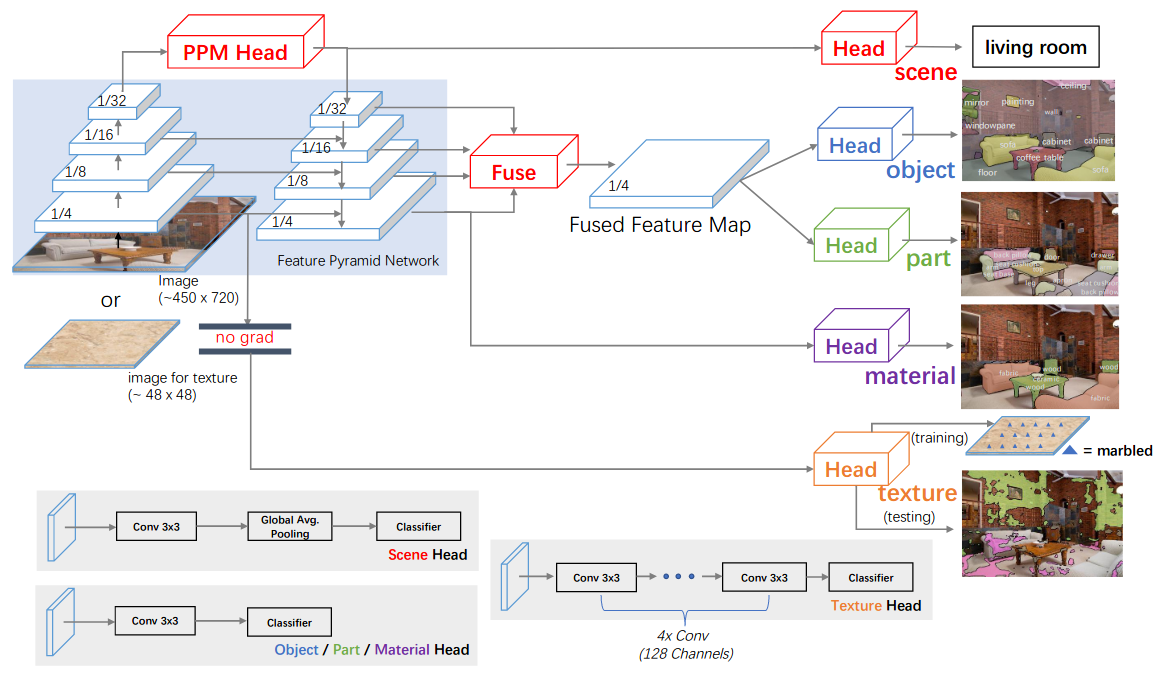 +
+ +
+