translated by<Hoching>
Malini Das is a software engineer who is passionate about developing quickly (but safely!), and solving cross-functional problems. She has worked at Mozilla as a tools engineer and is currently honing her skills at Twitch. Follow Malini on Twitter or on her blog.
Malini Das 是一個熱衷於快速(但安全!)的開發,並解決跨功能問題的軟體工程師。她曾在 Mozilla 擔任工具工程師,現在則在 Twitch 磨練他的技能。想知道更多有關 Malini,可以參見 Twitter或她的 blog。
When developing software, we want to be able to verify that our new features or bug fixes are safe and work as expected. We do this by running tests against our code. Sometimes, developers will run tests locally to verify that their changes are safe, but developers may not have the time to test their code on every system their software runs in. Further, as more and more tests are added the amount of time required to run them, even only locally, becomes less viable. Because of this, continuous integration systems have been created.
當開發軟體的時候,我們會希望能驗證新的功能或錯誤修復是否安全且依照預期,為此我們會對程式碼執行一些測試。有時開發者會在本地端跑測試來確認修改是安全的,但或許不會有時間在每個可能運行的系統上都測試過。再者,隨著測試的項目越來越多,所需耗費的時間隨之增加,甚至連本地端測試都越來越難執行。綜合以上原因,持續性整合系統便誕生了。
Continuous Integration (CI) systems are dedicated systems used to test new code. Upon a commit to the code repository, it is the responsibility of the continuous integration system to verify that this commit will not break any tests. To do this, the system must be able to fetch the new changes, run the tests and report its results. Like any other system, it should also be failure resistant. This means if any part of the system fails, it should be able to recover and continue from that point.
持續性整合系統(Continuous Integration, CI)是一個致力於測試新程式碼的系統。在程式被提交到版本庫之後,持續性整合系統就負責確認這次的提交能否通過全部的測試。要做到這件事,系統必須能抓到最新的改動、執行測試和回報測試的結果。就像其他系統一樣,它也必須要能夠容忍錯誤,也就說:如果某個系統的部分失敗了,它要有辦法修復且從剛剛失敗的地方繼續下去。
This test system should also handle load well, so that we can get test results in a reasonable amount of time in the event that commits are being made faster than the tests can be run. We can achieve this by distributing and parallelizing the testing effort. This project will demonstrate a small, bare-bones distributed continuous integration system that is designed for extensibility.
這個測試系統也必須能有效處理負荷,這樣一來即使在程式碼提交比測試執行還快速的情況下,也能夠在合理的時間內得到測試結果。我們可以藉由分散式和平行處理來達到這樣的效果。本專案將示範一個小規模的基礎分散式持續性整合系統,可以基於這樣的設計來延伸。
This project uses Git as the repository for the code that needs to be tested. Only standard source code management calls will be used, so if you are unfamiliar with Git but are familiar with other version control systems (VCS) like svn or Mercurial, you can still follow along.
本專案使用Git做為待測試程式的版本庫,不過只有標準的程式碼處理指令才會被使用,所以如果你不太熟悉Git,但熟悉其他版本控制系統像是svn或 Mercurial,你還是可以跟著操作。
Due to the limitations of code length and unittest, I simplified test discovery. We will only run tests that are in a directory named tests within the repository.
由於程式碼長度和單元測試的限制,我簡化了 test discovery,我們只會執行版本庫中在 tests 資料夾裡的測試。
Continuous integration systems monitor a master repository which is usually hosted on a web server, and not local to the CI's file systems. For the cases of our example, we will use a local repository instead of a remote repository.
持續性整合系統通常是監控一個在架設在網頁伺服器的 master 版本庫,兩者不是在同一個本地端。然而在我們的範例程式中,會使用本地端的版本庫來取代遠端的版本庫。
Continuous integration systems need not run on a fixed, regular schedule. You can also have them run every few commits, or per-commit. For our example case, the CI system will run periodically. This means if it is set up to check for changes in five-second periods, it will run tests against the most recent commit made after the five-second period. It won't test every commit made within that period of time, only the most recent one.
持續性整合系統們不需要按照固定而規律的行程來執行。你也可以讓它們在每幾次提交之後,或是每個提交之後都執行。以我們的範例來說,這個持續性整合系統會定期去執行,這代表說,如果它被設定成每五秒去檢查一次,它就會在每五秒的週期之後,去執行最近一次的提交。它不會去執行週期中的每一次提交,只會執行最近一次的。
This CI system is designed to check periodically for changes in a repository. In real-world CI systems, you can also have the repository observer get notified by a hosted repository. Github, for example, provides "post-commit hooks" which send out notifications to a URL. Following this model, the repository observer would be called by the web server hosted at that URL to respond to that notification. Since this is complex to model locally, we're using an observer model, where the repository observer will check for changes instead of being notified.
這個持續性整合系統被設計成定期去檢查版本庫的變化。在實際的持續性整合系統中,你也可以讓版本庫監控器接收版本庫的通知,例如:Github 提供了 "post-commit hooks" 來發送通知到一個網址。以這個模型來說,版本庫監控器就可以被該網址的網頁伺服器通知,進而做出回應。由於這對本地端模擬起來比較複雜,我們使用的監控器模型將會去主動確認是否有更動,而不是被通知。
CI systems also have a reporter aspect, where the test runner reports its results to a component that makes them available for people to see, perhaps on a webpage. For simplicity, this project gathers the test results and stores them as files in the file system local to the dispatcher process.
持續性整合系統在回報系統的方面,測試執行器會回報它的測試結果給一個可以被人們看到的元件,或許是網頁。為了簡化,這個專案是將測試結果們搜集起來存成檔案,並將檔案們放在分配器本地端的檔案系統裡。
Note that the architecture this CI system uses is just one possibility among many. This approach has been chosen to simplify our case study into three main components.
要注意的是,這篇文章中使用的持續性整合系統架構只是很多種可能裡的其中一種。此處選用這個方法是為了簡化我們的案例探討到三個主要的元件。
The basic structure of a continuous integration system consists of three components: an observer, a test job dispatcher, and a test runner. The observer watches the repository. When it notices that a commit has been made, it notifies the job dispatcher. The job dispatcher then finds a test runner and gives it the commit number to test.
持續性整合系統基本的組成架構包含三個元件:一個監控器、一個測試工作分配器和一個測試執行器。監控器會監視版本庫,當有新的提交的時候,它就會通知工作分配器。工作分配器會再找到一個測試執行器並給它提交號來做測試。
There are many ways to architect a CI system. We could have the observer, dispatcher and runner be the same process on a single machine. This approach is very limited since there is no load handling, so if more changes are added to the repository than the CI system can handle, a large backlog will accrue. This approach is also not fault-tolerant at all; if the computer it is running on fails or there is a power outage, there are no fallback systems, so no tests will run. The ideal system would be one that can handle as many test jobs as requested, and will do its best to compensate when machines go down.
架構一個持續性整合系統有很多方式,我們可以讓監控器、分配器和執行器都是同一個機器下的同一個程序。但這個方法會非常侷限,因為沒有負載處理的機制,所以如果版本庫有大於持續性整合系統可以處理的變動,就會累積很多未處理的提交。此外,這個方法也無法容忍錯誤,如果電腦在執行時有錯誤或是因為電源問題停運,它並沒有退回的系統,所以就不會執行測試。理想上的系統應該是可以處理被請求的所有測試工作,而且當機器停運時會盡力去挽救。
To build a CI system that is fault-tolerant and load-bearing, in this project, each of these components is its own process. This will let each process be independent of the others, and let us run multiple instances of each process. This is useful when you have more than one test job that needs to be run at the same time. We can then spawn multiple test runners in parallel, allowing us to run as many jobs as needed, and prevent us from accumulating a backlog of queued tests.
為了建造一個可容認錯誤而且可承受負載的持續性整合系統,在這個專案中,每個元件都是個別的程序。這會讓每個程序之間是獨立的,而且每個程序還可以執行數個實例。當有很多測試工作要同時執行時,這會很有用。我們可以平行產生很多個測試執行器,讓我們可以根據需求運行多個工作,防止我們累積排隊等待進行的工作無法完成。
In this project, not only do these components run as separate processes, but they also communicate via sockets, which will let us run each process on a separate, networked machine. A unique host/port address is assigned to each component, and each process can communicate with the others by posting messages at the assigned addresses.
在這個專案裡,不只元件們以分開的程序來執行,它們之間的溝通也是藉由 socket,讓我們可以在分開的、有網路的機器上執行每個程式。一個獨一無二的 host/port 位址會被指定給每一個元件,每一個程序就可以藉由傳送訊息到指定的位址來做溝通。
This design will let us handle hardware failures on the fly by enabling a distributed architecture. We can have the observer run on one machine, the test job dispatcher on another, and the test runners on another, and they can all communicate with each other over a network. If any of these machines go down, we can schedule a new machine to go up on the network, so the system becomes fail-safe.
這個設計藉由分散式的架構,讓我們有辦法可以動態地處理硬體上的故障。我們可以讓監測器在一台機器上運行,分配器和測試執行器又各別在不同的機器上運行,它們之間可以藉由網路來跟彼此溝通。如果任何一台機器關閉了,我們可以排定一台新的機器在該網路啟動,那整個系統就變得可以容忍故障。
註: on the fly?
This project does not include auto-recovery code, as that is dependent on your distributed system's architecture, but in the real world, CI systems are run in a distributed environment like this so they can have failover redundancy (i.e., we can fall back to a standby machine if one of the machines a process was running on becomes defunct).
此專案並不包含自動修復的程式碼,因為那和你的分散式系統架構有關。但在現實世界中,持續性整合系統都是運行在一個分散式的環境,所以會有故障轉移(也就是說,如果有其中一台正在執行程式的機器故障了,我們可以在一台備用的機器上將系統、組件、服務恢復到故障之前的組態)。
註:故障轉移
For the purposes of this project, each of these processes will be locally and manually started distinct local ports.
為了本專案的目標,每一個程序都會在本地端不同的 port 被手動啟動。
This project contains Python files for each of these components: the repository observer (
repo_observer.py), the test job dispatcher (dispatcher.py), and the test runner (test_runner.py). Each of these three processes communicate with each other using sockets, and since the code used to transmit information is shared by all of them, there is ahelpers.pyfile that contains it, so each process imports the communicate function from here instead of having it duplicated in the file.
這個專案包含了每個元件的 Python 檔案:版本庫觀測器(repo_observer.py)、測試工作分配器(dispatcher.py)和測試執行器(test_runner.py)。這三個程序使用 socket 來彼此溝通。又因為用來傳送訊息的程式碼是共用的,包含在 helpers.py 檔案裡,所以每個程序都會從這裡匯入溝通的函式,而不是再複製一份。
There are also bash script files used by these processes. These script files are used to execute bash and git commands in an easier way than constantly using Python's operating system-level modules like os and subprocess.
在這些程序中也用到 bash 腳本,這些腳本檔案被用來執行 bash 和 git 的指令。因為這會比經常使用 Python 的作業系統層級模組(像是 os 和 subprocess) 來的簡單。
Lastly, there is a tests directory, which contains two example tests the CI system will run. One test will pass, and the other will fail.
最後,會有一個測試的資料夾,裡面包含了此持續性整合系統將會執行的兩個範例測試。一個測試會通過,另一個則會失敗。
While this CI system is ready to work in a distributed system, let us start by running everything locally on one computer so we can get a grasp on how the CI system works without adding the risk of running into network-related issues. If you wish to run this in a distributed environment, you can run each component on its own machine.
雖然這個持續性整合系統是準備用在分散式系統上的,在此我們會將所有東西在本地端執行,以便讓我們可以理解持續性整合系統式如何運作的,而不會有網路相關問題的風險。如果你希望將系統執行在分散式的環境中,你可以讓每個元件運行在它自己的一台機器上。
Continuous integration systems run tests by detecting changes in a code repository, so to start, we will need to set up the repository our CI system will monitor.
持續性整合系統藉由偵測程式碼版本庫的變動來執行測試,所以要啟動系統,我們就必須設定我們持續性整合系統要監控的版本庫。
Let's call this test_repo:
讓我們叫它 test_repo:
$ mkdir test_repo
$ cd test_repo
$ git init
This will be our master repository. This is where developers check in their code, so our CI should pull this repository and check for commits, then run tests. The thing that checks for new commits is the repository observer.
這會是我們的 master 版本庫,這也是開發者寫入他們程式碼的地方,所以我們的持續性整合系統會從此版本庫 pull,並確認提交,然後執行測試。版本庫監控器會確認新的提交。
註: check in?
The repository observer works by checking commits, so we need at least one commit in the master repository. Let’s commit our example tests so we have some tests to run.
版本庫監控器的工作就是確認提交,所以我們在 master 版本庫至少要有一個提交。把範例中的 tests 提交上去後,我們就可以執行一些測試。
Copy the tests folder from this code base to test_repo and commit it:
把 tests 資料夾中的程式碼複製到 test_repo,接著提交它:
$ cp -r /this/directory/tests /path/to/test_repo/
$ cd /path/to/test\_repo
$ git add tests/
$ git commit -m ”add tests”
Now you have a commit in the master repository.
現在你在 master 版本庫有了一個提交。
The repo observer component will need its own clone of the code, so it can detect when a new commit is made. Let's create a clone of our master repository, and call it
test_repo_clone_obs:
版本庫監控器元件會需要自己有一份複製的程式碼,這樣當有新的提交的時候,它才能偵測到。因此我們建立一份 master 版本庫的副本,把它叫作 test_repo_clone_obs:
$ git clone /path/to/test_repo test_repo_clone_obs
The test runner will also need its own clone of the code, so it can checkout the repository at a given commit and run the tests. Let's create another clone of our master repository, and call it test_repo_clone_runner:
測試執行器也會需要自己有一份程式碼副本,以便它查看特定的提交,並執行測試。因此我們再建立一份 master 版本庫的副本,把它叫作 test_repo_clone_runner:
$ git clone /path/to/test_repo test_repo_clone_runner
The repository observer monitors a repository and notifies the dispatcher when a new commit is seen. In order to work with all version control systems (since not all VCSs have built-in notification systems), this repository observer is written to periodically check the repository for new commits instead of relying on the VCS to notify it that changes have been made.
當有新的程式提交時,版本庫監控器負責監控版本庫和通知分配器。為了與所有的版本控制系統相容(因為並不是所有版控系統都有內建通知系統),版本庫監控器被設計成定期去檢查版本庫是否有新的提交,而不是倚靠版控系統來通知更新。
The observer will poll the repository periodically, and when a change is seen, it will tell the dispatcher the newest commit ID to run tests against. The observer checks for new commits by finding the current commit ID in its repository, then updates the repository, and lastly, it finds the latest commit ID and compares them. For the purposes of this example, the observer will only dispatch tests against the latest commit. This means that if two commits are made between a periodic check, the observer will only run tests against the latest commit. Usually, a CI system will detect all commits since the last tested commit, and will dispatch test runners for each new commit, but I have modified this assumption for simplicity.
監控器會定期輪詢版本庫,確認是否有變更,並將最新的提交編號告知分配器來做測試。監控器確認是否有新提交的方法是:找出目前版本庫的提交編號,然後更新版本庫,最後找出最近的提交編號來做比對。為了達到這個範例的目的,監控器將只會分配最新的提交。也就是說,如果在定期檢查中間的發生了兩次提交,監控器只會對最新的提交做測試。通常持續性整合系統會偵測自從上一次測試之後的所有提交,而且會將每個提交都分配給測試執行器,但我為了簡化,修改了這個假設。
The observer must know which repository to observe. We previously created a clone of our repository at
/path/to/test_repo_clone_obs. The observer will use this clone to detect changes. To allow the repository observer to use this clone, we pass it the path when we invoke therepo_observer.pyfile. The repository observer will use this clone to pull from the main repository.
監控器需要知道要觀察哪個版本庫,所以我們事先複製了一份版本庫到 /path/to/test_repo_clone_obs,監控器會用這個副本來偵測變化。為了讓監控器能使用這個副本,我們會在啟動 repo_observer.py 時將檔案位址傳給它。版本庫監控器就可以利用這個副本來從主要版本庫抓取檔案。
We must also give the observer the dispatcher's address, so the observer may send it messages. When you start the repository observer, you can pass in the dispatcher's server address using the --dispatcher-server command line argument. If you do not pass it in, it will assume the default address of localhost:8888.
因為監控器可能會傳送訊息給分配器,我們也必須把分配器的位址給它。當我們啟動版本庫監控器時,你可以利用命令列(command-line)帶參數 --dispatcher-server 來傳遞分配器伺服器的位址。如果你沒有帶該參數的話,程式會假設預設位址為 localhost:8888。
def poll():
parser = argparse.ArgumentParser()
parser.add_argument("--dispatcher-server",
help="dispatcher host:port, " \
"by default it uses localhost:8888",
default="localhost:8888",
action="store")
parser.add_argument("repo", metavar="REPO", type=str,
help="path to the repository this will observe")
args = parser.parse_args()
dispatcher_host, dispatcher_port = args.dispatcher_server.split(":")
Once the repository observer file is invoked, it starts the poll() function. This function parses the command line arguments, and then kicks off an infinite while loop. The while loop is used to periodically check the repository for changes. The first thing it does is call the update_repo.sh Bash script.
一旦版本庫監控器被啟動,它就會啟動 poll() 函式,這個函式會解析命令列帶的參數,然後開始無限迴圈。這個無窮迴圈是用來定期檢查版本庫是否有變動,它所做的第一件事就是呼叫 Bash 腳本:update_repo.sh。
while True:
try:
# call the bash script that will update the repo and check
# for changes. If there's a change, it will drop a .commit_id file
# with the latest commit in the current working directory
subprocess.check_output(["./update_repo.sh", args.repo])
except subprocess.CalledProcessError as e:
raise Exception("Could not update and check repository. " +
"Reason: %s" % e.output)
The update_repo.sh file is used to identify any new commits and let the repository observer know. It does this by noting what commit ID we are currently aware of, then pulls the repository, and checks the latest commit ID. If they match, no changes are made, so the repository observer doesn't need to do anything, but if there is a difference in the commit ID, then we know a new commit has been made. In this case, update_repo.sh will create a file called .commit_id with the latest commit ID stored in it.
update_repo.sh 這個檔案是用來確認是否有新的提交,若有的話會告知版本庫監控器。它的做法是記下我們目前已知的提案編號,然後從版本庫拉下檔案,然後確認最新的提案編號。如果編號一致的話,代表檔案沒有更新,所以版本庫監控器就不需做任何事;但如果提案編號有差異,我們就知道有新的提交,在這個情況下,update_repo.sh 會創建一個名為 .commit_id 的檔案,並將最新的提案編號存在其中。
A step-by-step breakdown of update_repo.sh is as follows. First, the script sources the run_or_fail.sh file, which provides the run_or_fail helper method used by all our shell scripts. This method is used to run the given command, or fail with the given error message.
接著我們一步步分解 update_repo.sh。首先,這個腳本 source 了 run_or_fail.sh 檔案,在整個腳本中都會用到它所提供的 run_or_fail 這個輔助函式。這個函式用來執行給予的命令,或是在失敗的時候給出錯誤訊息。
#!/bin/bash
source run_or_fail.sh
註: source
Next, the script tries to remove a file named
.commit_id. Since updaterepo.sh is called infinitely by therepo_observer.pyfile, if we previously had a new commit, then.commit_idwas created, but holds a commit we already tested. Therefore, we want to remove that file, and create a new one only if a new commit is found.
接著,這個腳本試著移除 .commit_id 這個檔案。因為在 repo_observer.py 會無止境地呼叫 updaterepo.sh,如果我們之前有一個提交,那 .commit_id 就已經被創建,但其實是存著我們已經測試過的提交。因此,我們會先將該檔案移除,一直到有新的提交才創建新的檔案。
bash rm -f .commit_id
After it removes the file (if it existed), it verifies that the repository we are observing exists, and then resets it to the most recent commit, in case anything caused it to get out of sync.
在移除該檔案(如果存在)之後,程式會確認我們正在觀察的版本庫是否存在,且重置它到最近的提交,以免有任何沒同步到的的情況發生。
run_or_fail "Repository folder not found!" pushd $1 1> /dev/null
run_or_fail "Could not reset git" git reset --hard HEAD
It then calls git log and parses the output, looking for the most recent commit ID.
接下來會呼叫 git log 並解析輸出,尋找最近一次的提交編號。
COMMIT=$(run_or_fail "Could not call 'git log' on repository" git log -n1)
if [ $? != 0 ]; then
echo "Could not call 'git log' on repository"
exit 1
fi
COMMIT_ID=`echo $COMMIT | awk '{ print $2 }'`
Then it pulls the repository, getting any recent changes, then gets the most recent commit ID.
然後程式抓取版本庫最近的所有變更,並取得最近一次的提交編號。
run_or_fail "Could not pull from repository" git pull
COMMIT=$(run_or_fail "Could not call 'git log' on repository" git log -n1)
if [ $? != 0 ]; then
echo "Could not call 'git log' on repository"
exit 1
fi
NEW_COMMIT_ID=`echo $COMMIT | awk '{ print $2 }'`
Lastly, if the commit ID doesn't match the previous ID, then we know we have new commits to check, so the script stores the latest commit ID in a .commit_id file.
最後,如果提交編號和之前的編號不一致,我們就知道有新的提交必須要測試,此腳本也會將最近一次的提交編號寫入檔案 .commit_id。
# if the id changed, then write it to a file
if [ $NEW_COMMIT_ID != $COMMIT_ID ]; then
popd 1> /dev/null
echo $NEW_COMMIT_ID > .commit_id
fi
When
update_repo.shfinishes running inrepo_observer.py, the repository observer checks for the existence of the.commit_idfile. If the file does exist, then we know we have a new commit, and we need to notify the dispatcher so it can kick off the tests. The repository observer will check the dispatcher server's status by connecting to it and sending a 'status' request, to make sure there are no problems with it, and to make sure it is ready for instruction.
當 repo_observer.py 裡的 update_repo.sh 執行完之後,版本庫監控器會去檢查 .commit_id 這個檔案是否存在。如果存在的話代表有新的提交,我們就必須要通知分配器開始執行測試。版本庫監控器會藉由連接分配器伺服器,並發送 'status' 請求,來確認的它的狀態是否正常,還有是否準備好接收更多指示。
if os.path.isfile(".commit_id"):
try:
response = helpers.communicate(dispatcher_host,
int(dispatcher_port),
"status")
except socket.error as e:
raise Exception("Could not communicate with dispatcher server: %s" % e)
If it responds with "OK", then the repository observer opens the
.commit_idfile, reads the latest commit ID and sends that ID to the dispatcher, using adispatch:<commit ID>request. It will then sleep for five seconds and repeat the process. We'll also try again in five seconds if anything went wrong along the way.
如果分配器回覆 "OK",那版本庫監控器就會開啟檔案 .commit_id 讀取最近一次的提交編號,然後用請求 dispatch:<commit ID> 將編號發送給分配器。接著版本庫監控器會休眠五秒然後重複以上程序。如果中間出現任何錯誤也會在五秒後重試。
if response == "OK":
commit = ""
with open(".commit_id", "r") as f:
commit = f.readline()
response = helpers.communicate(dispatcher_host,
int(dispatcher_port),
"dispatch:%s" % commit)
if response != "OK":
raise Exception("Could not dispatch the test: %s" %
response)
print "dispatched!"
else:
raise Exception("Could not dispatch the test: %s" %
response)
time.sleep(5)
The repository observer will repeat this process forever, until you kill the process via a KeyboardInterrupt (Ctrl+c), or by sending it a kill signal.
版本庫監控器會一直重複這個程序直到你用 KeyboardInterrupt(Ctrl+c)或是用 kill 將程序終止。
The dispatcher is a separate service used to delegate testing tasks. It listens on a port for requests from test runners and from the repository observer. It allows test runners to register themselves, and when given a commit ID from the repository observer, it will dispatch a test runner against the new commit. It also gracefully handles any problems with the test runners and will redistribute the commit ID to a new test runner if anything goes wrong.
分配器是一套獨立運行的系統,用來委派測試的任務。它會去監聽一個連接埠,以接收來自測試執行器或是版本庫監控器的請求。分配器也允許測試執行器來註冊。當分配器從版本庫監控器取得一個提交編號,它會分配一個測試執行器來負責這個新的提交。分配器能夠優雅地處理任何有關測試執行器的問題,如果中途發生錯誤,也會將該提案編號重新分配給新的測試執行器。
When
dispatch.pyis executed, the serve function is called. First it parses the arguments that allow you to specify the dispatcher's host and port:
當 dispatch.py 被執行,serve 這個函式會被呼叫。首先你可以在參數中帶入分配器的位址和埠號。
def serve():
parser = argparse.ArgumentParser()
parser.add_argument("--host",
help="dispatcher's host, by default it uses localhost",
default="localhost",
action="store")
parser.add_argument("--port",
help="dispatcher's port, by default it uses 8888",
default=8888,
action="store")
args = parser.parse_args()
This starts the dispatcher server, and two other threads. One thread runs the
runner_checkerfunction, and other runs theredistributefunction.
這會開始執行分配器伺服器和另外兩個線程,其中一個線程運行 runner_checker 函式,另一個會運行 redistribute 函式。
server = ThreadingTCPServer((args.host, int(args.port)), DispatcherHandler)
print `serving on %s:%s` % (args.host, int(args.port))
...
runner_heartbeat = threading.Thread(target=runner_checker, args=(server,))
redistributor = threading.Thread(target=redistribute, args=(server,))
try:
runner_heartbeat.start()
redistributor.start()
# Activate the server; this will keep running until you
# interrupt the program with Ctrl+C or Cmd+C
server.serve_forever()
except (KeyboardInterrupt, Exception):
# if any exception occurs, kill the thread
server.dead = True
runner_heartbeat.join()
redistributor.join()
The runner_checker function periodically pings each registered test runner to make sure they are still responsive. If they become unresponsive, then that runner will be removed from the pool and its commit ID will be dispatched to the next available runner. The function will log the commit ID in the pending_commits variable.
runner_checker 這個函式會週期性地 ping 每個註冊的測試執行器來確認它們都有回應。假如有測試執行器沒有回應,那該執行器就會被從執行器池中移除,而它被分配到的提交編號也會被重新分配給下一個有空的執行器。這個函式會將該提案編號紀錄在 pending_commits 變數。
def runner_checker(server):
def manage_commit_lists(runner):
for commit, assigned_runner in server.dispatched_commits.iteritems():
if assigned_runner == runner:
del server.dispatched_commits[commit]
server.pending_commits.append(commit)
break
server.runners.remove(runner)
while not server.dead:
time.sleep(1)
for runner in server.runners:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
response = helpers.communicate(runner["host"],
int(runner["port"]),
"ping")
if response != "pong":
print "removing runner %s" % runner
manage_commit_lists(runner)
except socket.error as e:
manage_commit_lists(runner)
The redistribute function is used to dispatch the commit IDs logged in pending_commits. When redistribute runs, it checks if there are any commit IDs in pending_commits. If so, it calls the dispatch_tests function with the commit ID.
redistribute 函式是用來分配被記錄在 pending_commits 的提案編號們。它會確認在 pending_commits 裡是否有任何提案編號,若有的話,它就會用該提案編號呼叫 dispatch_tests。
def redistribute(server):
while not server.dead:
for commit in server.pending_commits:
print "running redistribute"
print server.pending_commits
dispatch_tests(server, commit)
time.sleep(5)
The
dispatch_testsfunction is used to find an available test runner from the pool of registered runners. If one is available, it will send a runtest message to it with the commit ID. If none are currently available, it will wait two seconds and repeat this process. Once dispatched, it logs which commit ID is being tested by which test runner in thedispatched_commitsvariable. If the commit ID is in thepending_commitsvariable,dispatch_testswill remove it since it has already been successfully re-dispatched.
dispatch_tests 這個函式會從註冊的執行器池中找到有空的測試執行器。當其中一個執行器有空時,分配器就會送一個執行測試的訊息加上提交的編號給它。如果沒有任何執行器有空,它就會等待兩秒鐘,然後重複以上程序。一旦測試任務分配好了,分配器就會在 dispatched_commits 變數記錄下哪個提交編號是被哪個執行器測試。如果該提交編號被記在 pending_commits 變數裡,dispatch_tests 也會將它從中移除,因為它已經被成功地重新分配了。
def dispatch_tests(server, commit_id):
# NOTE: usually we don't run this forever
while True:
print "trying to dispatch to runners"
for runner in server.runners:
response = helpers.communicate(runner["host"],
int(runner["port"]),
"runtest:%s" % commit_id)
if response == "OK":
print "adding id %s" % commit_id
server.dispatched_commits[commit_id] = runner
if commit_id in server.pending_commits:
server.pending_commits.remove(commit_id)
return
time.sleep(2)
The dispatcher server uses the
SocketServermodule, which is a very simple server that is part of the standard library. There are four basic server types in theSocketServermodule:TCP,UDP,UnixStreamServerandUnixDatagramServer. We will be using a TCP-based socket server so we can ensure continuous, ordered streams of data between servers, as UDP does not ensure this.
分配器伺服器使用 SocketServer 模組,它是標準函式庫裡一個非常簡單的伺服器。模組裡有四種基本的伺服器種類:TCP, UDP, UnixStreamServer 和 UnixDatagramServer。我們將會使用以 TCP 為基礎的 socket 伺服器,以確保伺服器間的資料串流是連續且有序的,UDP 就無法做到這點。
The default
TCPServerprovided bySocketServercan only handle one request at a time, so it cannot handle the case where the dispatcher is talking to one connection, say from a test runner, and then a new connection comes in, say from the repository observer. If this happens, the repository observer would have to wait for the first connection to complete and disconnect before it would be serviced. This is not ideal for our case, since the dispatcher server must be able to directly and swiftly communicate with all test runners and the repository observer.
SocketServer 提供的預設 TCPServer 一次只能處理一個請求,所以當分配器正在和一個測試執行器連線溝通,這時有一個從版本庫監控器來的新連線,它就無法處理。如果以上情況發生,版本庫監控器就必須等到第一個連線完成且斷線才能被處理。這不是一個理想的情況,因為分配器伺服器應該要可以直接且流暢地和所有測試執行器還有版本庫監控器溝通。
In order for the dispatcher server to handle simultaneous connections, it uses the
ThreadingTCPServercustom class, which adds threading ability to the defaultSocketServer. This means that any time the dispatcher receives a connection request, it spins off a new process just for that connection. This allows the dispatcher to handle multiple requests at the same time.
為了讓分配器伺服器可以同時處理多個連線,它使用客製化的 ThreadingTCPServer 類別,此類別在預設的 SocketServer 上加上了線程的功能。這代表每次分配器接收到一個連線請求的時候,它就會衍生出一個新的程序對該連線做處理。這讓分配器可以同時處理多個請求。
註:此處的process是指?
class ThreadingTCPServer(SocketServer.ThreadingMixIn, SocketServer.TCPServer):
runners = [] # Keeps track of test runner pool
dead = False # Indicate to other threads that we are no longer running
dispatched_commits = {} # Keeps track of commits we dispatched
pending_commits = [] # Keeps track of commits we have yet to dispatch
The dispatcher server works by defining handlers for each request. This is defined by the
DispatcherHandlerclass, which inherits fromSocketServer'sBaseRequestHandler. This base class just needs us to define the handle function, which will be invoked whenever a connection is requested. The handle function defined inDispatcherHandleris our custom handler, and it will be called on each connection. It looks at the incoming connection request (self.requestholds the request information), and parses out what command is being requested of it.
分配器伺服器藉由定義每個請求的處理器來運作。這在 DispatcherHandler 類別中被定義,它繼承自 SocketServer 中的 BaseRequestHandler。這個基礎類別只需要我們去定義處理函式,該函式在有連線請求時就會被觸發。在 DispatcherHandler 類別中定義的處理函式是我們的客製化處理器,它會在每次連線時被呼叫,並去看送來的連線請求(self.request 存有請求的資訊),然後解析出是要請求執行什麼命令。
class DispatcherHandler(SocketServer.BaseRequestHandler):
"""
The RequestHandler class for our dispatcher.
This will dispatch test runners against the incoming commit
and handle their requests and test results
"""
command_re = re.compile(r"(\w+)(:.+)*")
BUF_SIZE = 1024
def handle(self):
self.data = self.request.recv(self.BUF_SIZE).strip()
command_groups = self.command_re.match(self.data)
if not command_groups:
self.request.sendall("Invalid command")
return
command = command_groups.group(1)
It handles four commands:
status,register,dispatch, andresults.statusis used to check if the dispatcher server is up and running.
它處理四個命令:status(狀態)、register(註冊)、dispatch(分配)和 results(結果)。status 是用來確認分配器伺服器是否已啟動且正在執行。
if command == "status":
print "in status"
self.request.sendall("OK")
In order for the dispatcher to do anything useful, it needs to have at least one test runner registered. When register is called on a host:port pair, it stores the runner's information in a list (the runners object attached to the
ThreadingTCPServerobject) so it can communicate with the runner later, when it needs to give it a commit ID to run tests against.
要讓分配器有用處,它至少需要一個測試執行器來註冊。當執行器以 host:port 成對來註冊時,分配器會將此資訊存在一個串列(執行器的物件會附加在 ThreadingTCPServer 的物件上),所以當它之後需要給予測試者提案編號來執行測試時,就可以藉此跟執行器溝通。
elif command == "register":
# Add this test runner to our pool
print "register"
address = command_groups.group(2)
host, port = re.findall(r":(\w*)", address)
runner = {"host": host, "port":port}
self.server.runners.append(runner)
self.request.sendall("OK")
dispatchis used by the repository observer to dispatch a test runner against a commit. The format of this command isdispatch:<commit ID>. The dispatcher parses out the commit ID from this message and sends it to the test runner.
dispatch 是讓版本庫監控器用來分配提案給測試執行器,此命令的形式是 dispatch:<commit ID>。分配器會從此訊息中解析出提案編號,然後送給測試執行器。
elif command == "dispatch":
print "going to dispatch"
commit_id = command_groups.group(2)[1:]
if not self.server.runners:
self.request.sendall("No runners are registered")
else:
# The coordinator can trust us to dispatch the test
self.request.sendall("OK")
dispatch_tests(self.server, commit_id)
resultsis used by a test runner to report the results of a finished test run. The format of this command isresults:<commit ID>:<length of results data in bytes>:<results>. The<commit ID>is used to identify which commit ID the tests were run against. The<length of results data in bytes>is used to figure out how big a buffer is needed for the results data. Lastly,<results>holds the actual result output.
results 是測試執行器用來回報執行完的測試結果,此命令的形式是 results:<commit ID>:<length of results data in bytes>:<results>。<commit ID> 是用來確認測試執行的提案編號;<length of results data in bytes> 說明了測試結果資料的大小;<result> 則存有實際的測試輸出結果。
elif command == "results":
print "got test results"
results = command_groups.group(2)[1:]
results = results.split(":")
commit_id = results[0]
length_msg = int(results[1])
# 3 is the number of ":" in the sent command
remaining_buffer = self.BUF_SIZE - \
(len(command) + len(commit_id) + len(results[1]) + 3)
if length_msg > remaining_buffer:
self.data += self.request.recv(length_msg - remaining_buffer).strip()
del self.server.dispatched_commits[commit_id]
if not os.path.exists("test_results"):
os.makedirs("test_results")
with open("test_results/%s" % commit_id, "w") as f:
data = self.data.split(":")[3:]
data = "\n".join(data)
f.write(data)
self.request.sendall("OK")
The test runner is responsible for running tests against a given commit ID and reporting the results. It communicates only with the dispatcher server, which is responsible for giving it the commit IDs to run against, and which will receive the test results.
測試執行器負責對接收到的提案編號執行測試,並回報測試結果。它只會和分配器溝通,而分配器則是負責給它提案編號去做測試,且接收測試的結果。
When the
test_runner.pyfile is invoked, it calls the serve function which starts the test runner server, and also starts a thread to run the dispatcher_checker function. Since this startup process is very similar to the ones described inrepo_observer.pyanddispatcher.py, we omit the description here.
當 test_runner.py 檔案被執行時,它會呼叫啟動測試執行器伺服器的函式,而且也會開始一個線程來執行 dispatcher_checker 函式。由於這個啟動過程和 repo_observer.py 及 dispatcher.py 非常類似,此處就省略敘述的部分。
The dispatcher_checker function pings the dispatcher server every five seconds to make sure it is still up and running. This is important for resource management. If the dispatcher goes down, then the test runner will shut down since it won't be able to do any meaningful work if there is no dispatcher to give it work or to report to.
dispatcher_checker 這個函式每五秒會去 ping 一次分配器伺服器來確認它是不是還活著且運作中,這對於資源管理來說相當重要,因為如果分配器關閉了,測試執行器將無法執行任何有意義的工作,因為它不能從分配器接收工作,也無法回報。
def dispatcher_checker(server):
while not server.dead:
time.sleep(5)
if (time.time() - server.last_communication) > 10:
try:
response = helpers.communicate(
server.dispatcher_server["host"],
int(server.dispatcher_server["port"]),
"status")
if response != "OK":
print "Dispatcher is no longer functional"
server.shutdown()
return
except socket.error as e:
print "Can't communicate with dispatcher: %s" % e
server.shutdown()
return
The test runner is a
ThreadingTCPServer, like the dispatcher server. It requires threading because not only will the dispatcher be giving it a commit ID to run, but the dispatcher will be pinging the runner periodically to verify that it is still up while it is running tests.
測試執行器像分配器伺服器一樣是一個 ThreadingTCPServer。它需要使用線程因為它不止需要接收分配器給它的提案編號來做測試,分配器在它執行測試時也會定期 ping 測試者以確認它還活著。
class ThreadingTCPServer(SocketServer.ThreadingMixIn, SocketServer.TCPServer):
dispatcher_server = None # Holds the dispatcher server host/port information
last_communication = None # Keeps track of last communication from dispatcher
busy = False # Status flag
dead = False # Status flag
The communication flow starts with the dispatcher requesting that the runner accept a commit ID to run. If the test runner is ready to run the job, it responds with an acknowledgement to the dispatcher server, which then closes the connection. In order for the test runner server to both run tests and accept more requests from the dispatcher, it starts the requested test job on a new thread.
這個溝通的流程是從分配器要求測試者接收一個提案編號並做測試。如果測試者準備好要執行這個工作,它就會向分配器伺服器回應確認訊息,分配器伺服器就會關閉連線。測試執行器伺服器為了要執行測試和接收更多來自分配器的訊息,它會在一條新的線程上開始做被指派的測試工作。
This means that when the dispatcher server makes a request (a ping, in this case) and expects a response, it will be done on a separate thread, while the test runner is busy running tests on its own thread. This allows the test runner server to handle multiple tasks simultaneously. Instead of this threaded design, it is possible to have the dispatcher server hold onto a connection with each test runner, but this would increase the dispatcher server's memory needs, and is vulnerable to network problems, like accidentally dropped connections.
這代表當分配器伺服器下了一個請求(在此情況下,ping 了一次)且期待收到回應,這件事會在另一個分開的線程上執行,因為測試執行器正忙於在它的線程上執行測試。這樣一來也讓測試執行器可以同時處理多個任務。如果不使用線程的設計,也是可以讓分配器一直和每個測試執行器保持連線,但這會增加分配器伺服器的記憶體需求,且對於網路的問題,像是意外地斷了連線,也會比較脆弱。
The test runner server responds to two messages from the dispatcher. The first is
ping, which is used by the dispatcher server to verify that the runner is still active.
測試執行器伺服器會對分配器的兩種訊息作出回應。第一個是 ping,是分配器伺服器用來確認執行器是否還活著。
class TestHandler(SocketServer.BaseRequestHandler):
...
def handle(self):
....
if command == "ping":
print "pinged"
self.server.last_communication = time.time()
self.request.sendall("pong")
The second is
runtest, which accepts messages of the formruntest:<commit ID>, and is used to kick off tests on the given commit. When runtest is called, the test runner will check to see if it is already running a test, and if so, it will return aBUSYresponse to the dispatcher. If it is available, it will respond to the server with anOKmessage, set its status as busy and run itsrun_testsfunction.
第二個是 runtest,會接收以 runtest:<commit ID> 形式傳送的訊息,用來開始執行某提交的測試。當 runtest 被呼叫,測試執行器會確認它自己是否正在執行測試,若是的話它就會回傳給分配器 BUSY 的回應。若測試執行器有空的話,它就會回覆給分配器 OK 的訊息,然後設定它的狀態為忙綠中,並且執行 run_tests 函式。
elif command == "runtest":
print "got runtest command: am I busy? %s" % self.server.busy
if self.server.busy:
self.request.sendall("BUSY")
else:
self.request.sendall("OK")
print "running"
commit_id = command_groups.group(2)[1:]
self.server.busy = True
self.run_tests(commit_id,
self.server.repo_folder)
self.server.busy = False
This function calls the shell script
test_runner_script.sh, which updates the repository to the given commit ID. Once the script returns, if it was successful at updating the repository we run the tests using unittest and gather the results in a file. When the tests have finished running, the test runner reads in the results file and sends it in a results message to the dispatcher.
這個函式呼叫 test_runner_script.sh 腳本,它會更新版本庫到指定的提交編號。一旦這個腳本回覆它已成功更新版本庫,我們就會使用單元測試來測試,並將結果統整在一個檔案中。當測試結束後,測試執行器會讀取測試結果的檔案,並用 results 的訊息來傳給分配器。
def run_tests(self, commit_id, repo_folder):
# update repo
output = subprocess.check_output(["./test_runner_script.sh",
repo_folder, commit_id])
print output
# run the tests
test_folder = os.path.join(repo_folder, "tests")
suite = unittest.TestLoader().discover(test_folder)
result_file = open("results", "w")
unittest.TextTestRunner(result_file).run(suite)
result_file.close()
result_file = open("results", "r")
# give the dispatcher the results
output = result_file.read()
helpers.communicate(self.server.dispatcher_server["host"],
int(self.server.dispatcher_server["port"]),
"results:%s:%s:%s" % (commit_id, len(output), output))
Here's test_runner_script.sh:
以下是 test_runner_script.sh:
#!/bin/bash
REPO=$1
COMMIT=$2
source run_or_fail.sh
run_or_fail "Repository folder not found" pushd "$REPO" 1> /dev/null
run_or_fail "Could not clean repository" git clean -d -f -x
run_or_fail "Could not call git pull" git pull
run_or_fail "Could not update to given commit hash" git reset --hard "$COMMIT"
In order to run test_runner.py, you must point it to a clone of the repository to run tests against. In this case, you can use the previously created /path/to/test_repo test_repo_clone_runner clone as the argument. By default, test_runner.py will start its own server on localhost using a port in the range 8900-9000, and will try to connect to the dispatcher server at localhost:8888. You may pass it optional arguments to change these values. The --host and --port arguments are used to designate a specific address to run the test runner server on, and the --dispatcher-server argument specifies the address of the dispatcher.
為了執行 test_runner.py,你必須指向一個版本庫的副本來執行測試。在這個情況下,你可以使用之前創建的 /path/to/test_repo test_repo_clone_runner 複本當作參數。test_runner.py 預設會在 localhost 啟動它自己的伺服器,使用 port 範圍 8900-9000,
且會和分配器伺服器在 localhost:8888 連線。你可以傳入參數來取代這些數值,但非強制性。--host 和 --port 參數都用來指派一個特定的位址給測試執行器伺服器做執行。--dispatcher-server 參數則指定了分配器的位址。
Figure 2.1 is an overview diagram of this system. This diagram assumes that all three files (
repo_observer.py,dispatcher.pyandtest_runner.py) are already running, and describes the actions each process takes when a new commit is made.
圖 2.1 是一個系統的概述圖,這個圖表假設三個檔案(repo_observer.py, dispatcher.py 和 test_runner.py)都已經啟動,而且描述有一個新的提交時,每一個程序所採取的動作。
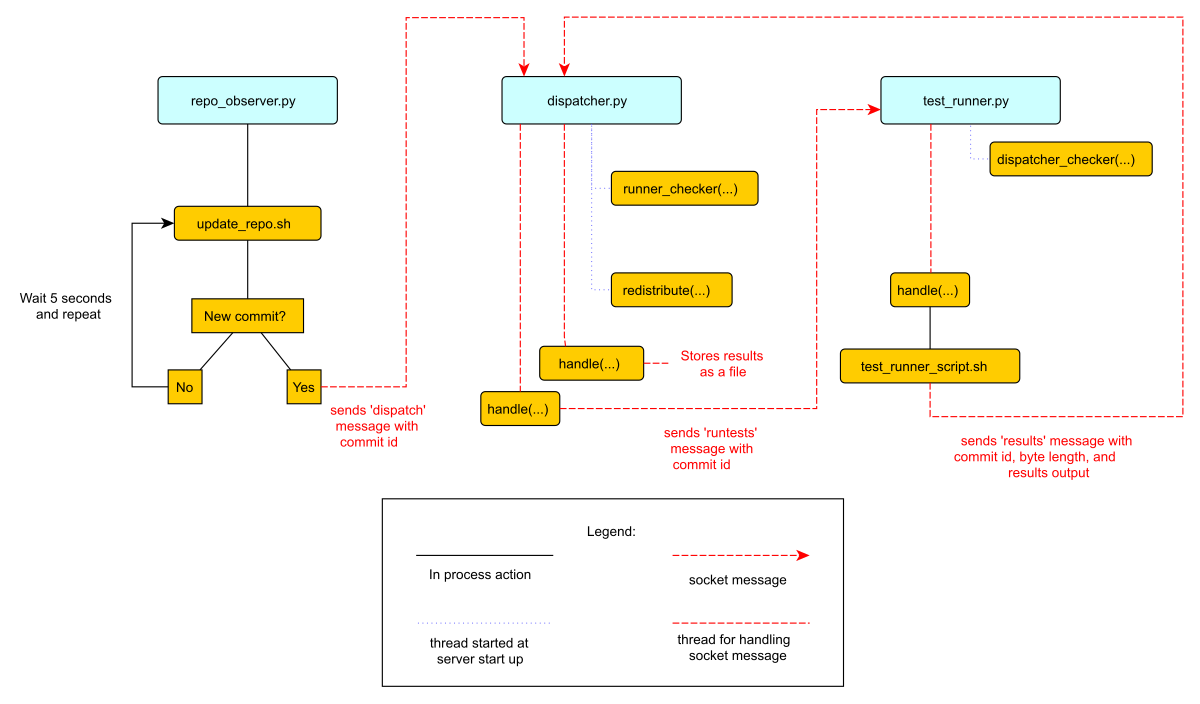
We can run this simple CI system locally, using three different terminal shells for each process. We start the dispatcher first, running on port 8888:
我們可以給三個程序使用不同的終端機殼層,在本地端執行這個簡單的持續性整合系統。我們由分配器開始,在 port 8888 執行:
$ python dispatcher.py
In a new shell, we start the test runner (so it can register itself with the dispatcher):
在一個新的殼層,我們啟動測試執行器(以讓它可以向分配器註冊它自己)
$ python test_runner.py <path/to/test_repo_clone_runner>
The test runner will assign itself its own port, in the range 8900-9000. You may run as many test runners as you like.
測試執行器會為它自己指定一個 port,範圍落在 8900-9000。你可以想執行幾個測試執行器就執行幾個。
Lastly, in another new shell, let's start the repo observer:
最後,在另一個新的殼層,我們來啟動版本庫監控器:
$ python repo_observer.py --dispatcher-server=localhost:8888 <path/to/repo_clone_obs>
Now that everything is set up, let's trigger some tests! To do that, we'll need to make a new commit. Go to your master repository and make an arbitrary change:
現在一切都設定好了,讓我們來觸發一些測試吧!為了觸發測試,我們必須執行一個新的提交,所以要去你的 master 版本庫做一些隨意的改動。
$ cd /path/to/test_repo
$ touch new_file
$ git add new_file
$ git commit -m"new file" new_file
Then repo_observer.py will realize that there's a new commit and notify the dispatcher. You can see the output in their respective shells, so you can monitor them. Once the dispatcher receives the test results, it stores them in a test_results/ folder in this code base, using the commit ID as the filename.
版本庫監控器將會發現有一個新的提交,然後會通知分配器。你可以在它們個別的殼層看到輸出,也就可以監控它們。一旦分配器接收到測試的結果,它會把結果存在test_results/ 資料夾,並用提交編號當作檔案名稱。
This CI system includes some simple error handling.
這個持續性整合系統包含了一些簡單的錯誤處理。
If you kill the
test_runner.pyprocess,dispatcher.pywill figure out that the runner is no longer available and will remove it from the pool.
如果你砍掉了test_runner.py程序,dispatcher.py 會察覺到執行器已經無法使用,就會將它從池中移除。
You can also kill the test runner, to simulate a machine crash or network failure. If you do so, the dispatcher will realize the runner went down and will give another test runner the job if one is available in the pool, or will wait for a new test runner to register itself in the pool.
你也可以把測試執行者砍掉,來模擬一台機器故障或是網路有問題。如果你這麼做的話,分配器會發現測試執行器關閉了,若池裡有其他可使用的測試執行器的話,它就會把工作分給該測試執行器,若沒有的話,它就會等到有新的測試執行器來註冊到池裡。
If you kill the dispatcher, the repository observer will figure out it went down and will throw an exception. The test runners will also notice, and shut down.
如果你把分配器砍掉,版本庫監控器將會察覺到它關閉了,並會丟出例外。測試執行器也會察覺到,就會關閉。
By separating concerns into their own processes, we were able to build the fundamentals of a distributed continuous integration system. With processes communicating with each other via socket requests, we are able to distribute the system across multiple machines, helping to make our system more reliable and scalable.
藉由個別去關注每個元件的程序,我們可以建構基本的分散式持續性整合系統。由於程序間是藉由 socket 請求溝通,我們可以將系統分散到多個機器上,幫助我們的系統更加可靠及可擴展。
Since the CI system is quite simple now, you can extend it yourself to be far more functional. Here are a few suggestions for improvements:
因為這個持續性整合系統目前相當精簡,你可以將它擴展地更加實用。以下是一些改良的建議:
The current system will periodically check to see if new commits are run and will run the most recent commit. This should be improved to test each commit. To do this, you can modify the periodic checker to dispatch test runs for each commit in the log between the last-tested and the latest commit.
目前的系統會定期確認是否有新的提交,且會執行最近一個提交的測試。這應該要改良成可以對每個提交都做測試。為了達成此目的,你可以修改定期的確認器,去對 log 中上一次測試的和最新提交之間的每一個提交,作分配並測試。
If the test runner detects that the dispatcher is unresponsive, it stops running. This happens even when the test runner is in the middle of running tests! It would be better if the test runner waited for a period of time (or indefinitely, if you do not care about resource management) for the dispatcher to come back online. In this case, if the dispatcher goes down while the test runner is actively running a test, instead of shutting down it will complete the test and wait for the dispatcher to come back online, and will report the results to it. This will ensure that we don't waste any effort the test runner makes, and that we will only run tests once per commit.
如果測試執行器偵測到分配器沒有回應,它就會停止執行,即使在執行測試的期間也會如此做。比較好的做法是測試執行器會等一段時間(或是永久等待,如果你不在意資源的管理),到分配器重新上線,在這個情況下,如果分配器在測試執行器執行測試時關閉了,執行器將會把測試完成,並等待分配器重新上線,然後把結果回報。這會確保測試執行器的努力不會白費,且每一次的提交只會執行一次測試。
In a real CI system, you would have the test results report to a reporter service which would gather the results, post them somewhere for people to review, and notify a list of interested parties when a failure or other notable event occurs. You can extend our simple CI system by creating a new process to get the reported results, instead of the dispatcher gathering the results. This new process could be a web server (or can connect to a web server) which could post the results online, and may use a mail server to alert subscribers to any test failures.
在實際的持續性整合系統,你會需要將測試結果回報給收集結果的回報者服務系統。它會把測試結果傳到某個人們可以審閱的地方,而且當有錯誤或是需要通知的事件發生時,會通知名單中正在關注的群體。你可以擴展我們簡單的持續性整合系統,創建一個新的程序來回報結果,而不是讓分配器來收r集測試結果。這個新的程序可以是網路伺服器(或者可以連到網路伺服器),它可以將結果發佈上線,當有任何測試錯誤時,可以使用電子郵件伺服器去警告訂閱者。
Right now, you have to manually launch the test_runner.py file to start a test runner. Instead, you could create a test runner manager process which would assess the current load of test requests from the dispatcher and scale the number of active test runners accordingly. This process will receive the runtest messages and will start a test runner process for each request, and will kill unused processes when the load decreases.
目前你必須手動執行 test_runner.py 檔案來啟動一個測試執行器。取而代之地,你可以創建一個測試執行器的管理器程序,它可以獲取目前測試請求的負載量,然後據此來調整有效的測試執行器數量。這個程序會接收 runtest 的訊息,接著對於每個請求會啟動一個測試執行器程序,當負載降低時,也會砍掉沒用到的程序。
Using these suggestions, you can make this simple CI system more robust and fault-tolerant, and you can integrate it with other systems, like a web-based test reporter.
採用這些建議,你可以讓這個簡單的持續性整合系統更加穩定且更容錯。你也可以和其他的系統整合,像是 web-based 測試回報器。
If you wish to see the level of flexibility continuous integration systems can achieve, I recommend looking into Jenkins, a very robust, open-source CI system written in Java. It provides you with a basic CI system which you can extend using plugins. You may also access its source code through GitHub. Another recommended project is Travis CI, which is written in Ruby and whose source code is also available through GitHub.
如果你想知道持續性整合系統可以多有彈性,我推薦你去看 Jenkins,它是一個非常穩定、用Java寫的開源持續性整合系統。它提供了基本的持續性整合系統,你可以用插件來擴充,你也可以在 GitHub 取得它的原始碼。另一個推薦的專案是 Travis CI,它是用 Ruby 寫的,原始碼一樣可以在 GitHub 取得。
This has been an exercise in understanding how CI systems work, and how to build one yourself. You should now have a more solid understanding of what is needed to make a reliable distributed system, and you can now use this knowledge to develop more complex solutions.
這是一個了解持續性整合系統,且如何自己建立系統的練習。你應該對於如何做出一個可靠的分散式系統,有更深刻的了解。你也可以將這些知識用於開發更複雜的解決方案。
1. Bash is used because we need to check file existence, create files, and use Git, and a shell script is the most direct and easy way to achieve this. Alternatively, there are cross-platform Python packages you can use; for example, Python's os built-in module can be used for accessing the file system, and GitPython can be used for Git access, but they perform actions in a more roundabout way.