- 학습 목표 1. Index 복습하기
DB 검색 속도를 향상시켜주는 자료구조
특정 컬럼에 인덱스를 추가하면, 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다.
비유를 하자면,
- Data == 책의 내용
- Index == 책의 목차
- Row ID = 책의 페이지 번호
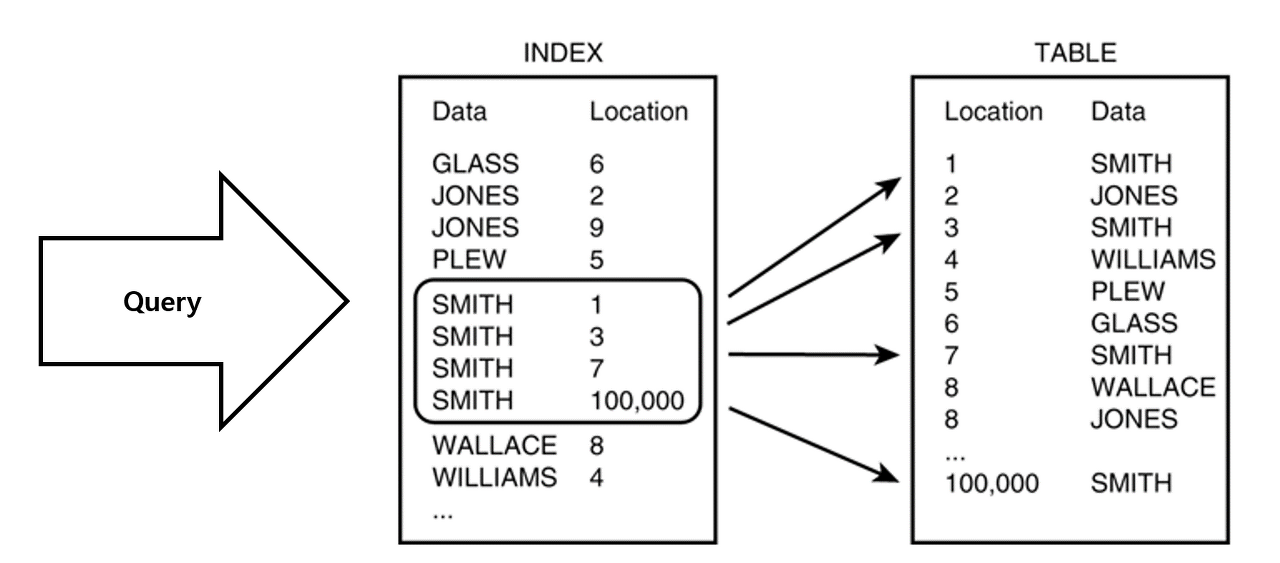
동작 방식
-- users 테이블에서 email로 검색
-- 인덱스 사용 시 실행 단계
SELECT * FROM users WHERE email = '[email protected]';
1. email 인덱스에서 '[email protected]' 검색
2. 해당 레코드의 Primary Key나 Row ID(물리적 주소) 확인
3. 해당 주소로 직접 이동
4. 완전한 데이터 로드장점
- 테이블 내의 데이터를 상단부터 하단까지 Full Table Scan 하는 것보다 훨씬 효율적이다.
- 인덱스 테이블은 정렬되어 있기 때문!
- 이미 데이터가 정렬되어 있기 때문에 본래 자원 소모가 큰 Order By절을 이용할시 비교적 적은 자원으로 이용이 가능하다.
- MIN, MAX 값을 효율적으로 찾아낼 수 있다. (정렬!되어 있기 때문에)
단점
-
위에서 계속 정렬정렬 했는데 그만큼 정렬을 유지시켜줘야 한다.
- INSERT, UPDATE, DELETE를 통해 데이터가 추가된다면 INDEX도 다시 정렬을 해줘야 한다.
- INSERT : 새로운 데이터에 대한 인덱스를 추가한다.
- UPDATE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행한다.
- DELETE : 기존의 인덱스는 사용하지 않음 처리, 갱신된 데이터에 대한 인덱스를 추가한다.
👉🏻 만약 어떤 테이블에 UPDATE, DELETE가 빈번하게 발생하면 사용하지 않는 인덱스가 쌓여 오히려 성능이 떨어지게 될 수도 있다.
- INSERT, UPDATE, DELETE를 통해 데이터가 추가된다면 INDEX도 다시 정렬을 해줘야 한다.
-
인덱스 관리를 위한 DB의 약 10% 정도에 해당하는 추가 저장공간이 필요하다.
-
테이블이 작은 경우에는 Full Table Scan이 더 효율적일 수 있다.
인덱스 생성 전략
- 테이블 내에 데이터가 고루 분포되어 있는 컬럼을 선택하자
- 최대한 중복이 없는 컬럼을 선택하자 (PK가 가장 좋겠당)
- 조건절에 자주 사용되는 컬럼을 선택하자
인덱스 구조
| Hash Table | B+Tree |
|---|---|
 |
 |
| - 컬럼 값과 물리적 주소를 (key, value) 형태로 저장 - 등호(=) 연산에 최적화 되어있음 - 시간 복잡도는 O(1) |
- 특정 컬럼에 인덱스를 생성하는 순간 이를 정렬함 - 정렬한 순서의 중간 쯤의 데이터를 Root 노드로 지정 - 맨 아래 Leaf 노드에 데이터와 데이터의 물리적 주소 정보를 저장 - Leaf 노드들은 LinkedList로 연결되어 있어 순차검색이 용이함 - 시간 복잡도는 O(𝑙𝑜𝑔2𝑛) |
- 커뮤니티 과제 유저 관련 데이터 RDS 연결하기
- 저번 주에 배운 DB 내용 중 INDEX 개념이 이해가 잘 되지 않아 추가로 공부를 해보았다. 저번보다는 이해가 되긴 했지만 한 번 봐서는 안 될 거 같고 꾸준히 봐줘야 할 거 같다. 왜 유독 얘가 이해가 안 될까 🤔
- 커뮤니티 유저만 RDS에 연결하려 했는데 게시글 조회까지 연결해 두었다. 이제 게시글 상세 조회부터 쭉 다시 연결해야겠다.